GPT21 - 论文精读学习笔记
论文地址:Language Models are Unsupervised Multitask Learners (2019)
代码地址:https://github.com/openai/gpt-2
Basic Architectures of LLMs
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
代码
复现的时候,可以着重看看博文7。
全文梗概
博文7 基于 Transformer 的更加 General 的语言模型。
博文1 文章探讨了GPT-2如何通过零样本学习在无需数据集标注的情况下执行多任务,介绍了语言模型的基本原理,包括预训练和微调,以及使用BPE编码的数据输入表示。实验结果显示,即使在无监督情况下,大量参数的模型也能展现良好的性能,特别是在儿童读物测试中,随着参数量增加,效果提升明显。
博文4 本文将常识推理和情感分析两项任务联系起来,采取更一般的方法。证明了语言模型可以在zero-shot下无需任何参数或架构的修改执行下游任务。
博文6 论文介绍的是 OpenAI 对 GPT 的一个改进模型 GPT-2,其模型结构与 GPT 相比几乎没有什么变化,只是让模型变得更大更宽,并且取消了 Fine-tuning 的步骤。也就是说 GPT-2 采用了一阶段的模型(预训练)代替了二阶段的模型(预训练+微调),并且在语言模型(文本摘要等)相关领域取得了不错的效果。
启发
在本文中,作者论证了这种方法的可行性,并证明了语言模型来相关领域具有很大的潜力。
背景知识
目前最好的 NLP 模型是结合无监督的 Pre-training 和监督学习的 Fune-tuning,但这种方法的缺点是针对某特定任务需要不同类型标注好的训练数据。作者认为这是狭隘的专家而不是通才,因此作者希望能够通过无监督学习训练出一个可以应对多种任务的通用系统。
博文7:
作者认为:
目前这种对单域数据集进行单任务训练的普遍性,是造成当前系统缺乏普遍性的主要原因;
另外,目前最好的方法是预训练模型 + 下游任务的监督训练。
本文是将二者结合起来,提供更加general的迁移方法,它可以使下游任务能够在zero-shot下实施,不需要参数或架构调整。证明了语言模型有在zero-shot下执行一系列任务的潜力。所以本文核心点有两个:
1 更加general的预训练模型;
2 zero-shot实施的多下游任务。
1 是2 的基础,2 是1 的应用。
任务设定的含义:给定一个文本中前面的所有单词,预测下一个单词。
有效性:不需要显示的监督学习,模型就可以用于非常多的任务(例外下谈,实际上这些例外很重要)且取得SOTA结果!
有效性来源:语言模型+数据集(规模巨大,多样性巨高)
缺点:
比之BERT,GPT有的问题,GPT-2都会继承;
无监督的通病:收敛慢;
问答、阅读理解、翻译和摘要任务成绩一般(语言建模任务成绩优秀)。
结论
传统的经验认为性能提升来自:大规模的数据集+大容量的模型+监督学习。
而这篇文章则用实验证明了在NLP领域中,性能提升可以来自:大规模的数据集 + 大容量的模型 + 无监督学习(语言模型)。
对于NLP而言,无标注的数据量非常大,因此挖掘出无监督学习的能力则成为了一个重要命题。
传统解决NLP问题的方式是针对一个任务,构造一个数据集,训练一个模型。
而GPT-2的出现,证明一个数据集,一个模型,可以很好地解决多个任务。
论文的主要贡献在于表明了“在一个足够大的、多样化的数据集上,训练一个超大的语言模型(high-capacity),能够很好泛化到其他任务上”。
简介
GPT-2是一个有15亿参数的模型。
GPT-2的想法是转向一个通用的系统,不需要进行数据集的标注就可以执行许多任务。
因为数据集的创建是很难的,我们很难继续将数据集的创建和目标的设计扩大到可能需要用现有的技术推动我们前进的程度。这促使我们去探索执行多任务学习的额外设置。
当前(2019年)性能最好的语言模型系统是通过预训练模型和微调完成的,预训练主要是自注意力模块去识别字符串的语意,而微调主要是通过语意去得出不同的结果;这样一来,我们在执行不同的任务时,只需要替换掉微调的那部分结构就可以;
而GPT-2证实了语言模型能够在不进行任何参数和结构修改的情况下,拥有执行下游任务的能力,这种能力获取的主要方式是强化语言模型的 zero-shot。
方法实现
在GPT1的基础上,GPT2中在多种NLP任务表示、训练数据准备、输入表示、模型设计四个方面上进行了改进实现。
多种NLP任务表示
论文关注的核心是NLP的语言模型,对于一个指定的NLP任务来说是通过条件概率p(output|input)来获取输出;
对于多任务学习来说,输出应该跟任务是相关的,即p(output|input,task);
参考论文【Multitask Learning as Question Answering】把多种NLP训练任务都变成了基于上下文的问答任务(Question-Answering-Over-Context)。
例如翻译任务表示成(translate to french, english text, french text),阅读理解任务表示成(answer the question, document question, answer)
训练数据
由于是多任务模型,需要构建尽可能大的和多样化的数据集,这里作者采用的是网络爬虫的方式进行解决。
为了避免文档质量不高,这里只采集了经过人类策划/过滤后的网页,手动过滤是困难的,所以作者只采集了Reddit社交平台上信息;
WebText(millions of webpages,40GB of text),来自Reddit。
最后生成的数据集包含了4500万个链接的文本子集;
文本是通过
Dragnet和newspaper进行提取的,经过重复数据删除和一些启发式的清理,该链接包含近800万文档,共计40GB文本,并且删除了所有的危机百科文档,因为它是其他数据集的通用数据源,并且可能会由于过度-而使分析复杂化。
作者认为目前的数据集往往都是针对某一特定任务,如 QA 领域的 SQuAD 2.0,机器翻译领域的 NIST04 和 WMT 2014 En-2-Fr等。而正是因为数据集的单一导致系统缺乏泛化性。
作者想通过尽可能地构建和利用足够大的且多样化的数据集,以保证最终的模型能够应用于多个不同的 NLP 任务中。
⇒ 为此,作者专门爬了 Reddit 上 > 3 karma 的外链作为数据源,同时去除 wiki 数据,最终数据大小共 40G。由于 Reddit 上的数据会包括各个领域,所以既保证了数据质量、数量又保证了数据的多样性。
作者从网上爬了一大堆语料,用来进行LM的pre-train,他们最后的数据集叫WebText,有800万左右的文档,40G的文本,并且还移除了Wikipedia的数据,因为后面要ZSL的任务里面有很多都是基于Wikipedia的语料的,这里其实就是保证了ZSL任务的前提。PS:ZSL就是Zero-shot Learning。
使用了自己准备的WebText数据集,使用了Dragnet和newspaper内容提取器。总共有800万文档,共40GB的文本数据。
Training Dataset是从网页抓取得到的相对高质量内容,数据集命名为WebText,是4500万链接的一个子集,包含超过800万个文档,共40GB的文本数据,其中Wikipedia的文档被过滤以避免与测试评估任务的数据重叠。
训练数据改造
为什么要改造啊?
因为GPT-1不是全自动的,里面有人为添加的特殊符号。而GPT-2是全自动的,所以不能再加一些符号了。
具体博文5的描述:
在 GPT-1 中,下游任务需要对不同任务的输入序列进行改造,在序列中加入了开始符、分隔符和结束符之类的特殊标识符,但是在 zero-shot 前提下,我们无法根据不同的下游任务去添加这些标识符,因为不进行额外的微调训练,模型在预测的时候根本不认识这些特殊标记。所以在 zero-shot 的设定下,不同任务的输入序列应该与训练时见到的文本长得一样,也就是以自然语言的形式去作为输入,例如下面两个任务的输入序列是这样改造的:
机器翻译任务:translate to french, { english text }, { french text } 阅读理解任务:answer the question, { document }, { question }, { answer }
GPT-2 的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
输入表示 Input Representation
在模型的输入方面,GPT-2采用的是Byte Pair Encoding(以下简称BPE)的Subword算法。
BPE是一种简单的数据压缩形式,可以有效地平衡词汇表大小和编码所需的token数量。它可以提高词表的空间使用效率,避免得到类似
dog. dog! dog?的词。BPE和我们之前提到的WordPiece的区别在于,WordPiece是基于生成Subword的,而BPE是基于贪心策略,每次都取最高频的字节对。
输入表示采用了BPE(Byte Pair Encoding)算法进行tokenizer,这里没有直接使用Unicode作为做为基础的词表,因为Unicode共有超过130000个字符太多了,这里采用了字节粒度的BPE,初始词表有256个(
且在字节级别上进行合并但是限制合并不同类型的字符以避免类似dog. dog! dog?的出现。这种表示方式能够结合词级别语言模型的优点和字节级别的泛化性能,更加灵活。
这里采用的是BPE编码方式(具体内容见论文&解说)我没看呢哦~ :)
模型设计
模型框架基本同GPT-1,有一点小改动,例如Layer normalization前移到每个子模块之前(顶层多加一层Layer normalization),初始化策略,扩大词表等。
在模型结构方面,整个GPT-2的模型框架与GPT-1相同,只是做了几个地方的调整,这些调整更多的是被当做训练时的trick,而不作为GPT-2的创新,具体为以下几点:
后置层归一化(post-norm)改为前置层归一化(pre-norm);
在模型方面相对于 GPT-1 来说几乎没有什么修改,只是加入了两个 Layer normalization,一个加在每个 sub-block 输入的地方,另一个加在最后一个 self-attention block 的后面。
post-norm v.s. pre-norm (主要差别)
两者的主要区别在于,post-norm将Transformer中每一个block的层归一化放在了残差层之后,而pre-norm将层归一化放在了每个block的输入位置,如下图所示:
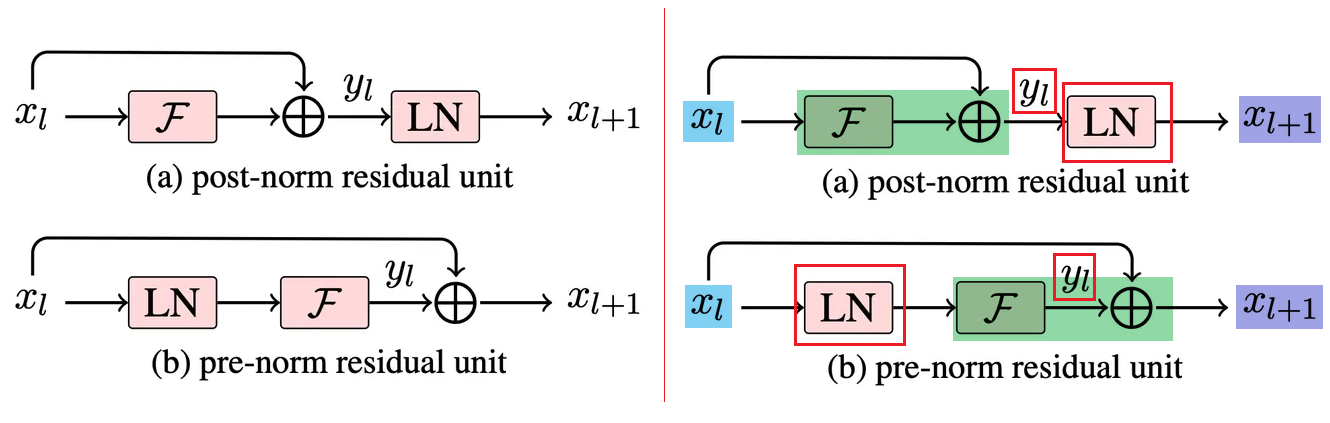
右图是左图的标记版本,红色方框圈住的内容是变化的内容
在模型最后一个自注意力层之后,额外增加一个层归一化;
调整参数的初始化方式,按残差层个数进行缩放,缩放比例为
同时考虑到模型深度对残差路径的累积问题,GPT-2采用了修正的初始化方法。在初始化时将残差层的权重缩放到
输入序列的最大长度从512扩充到1024。
此外,vocabulary的大小扩展到了50257,输入的上下文大小从512扩展到了1024,并且使用更大的batch size(512)。
GPT-1给出了一种半监督的训练方法,在GPT-2中针对如下问题做了升级:
以前机器学习训练代价大,往往先要指定训练任务和高质量的标注数据集,且要保证训练数据和测试数据的分布相同,不同任务间无法复用;GPT-2实现了一个更通用的系统,支持多种NLP任务的学习,实现了Zero-Shot.
大模型训练往往需要海量数据,准备高质量的标注数据集明显是不现实的;GPT-2中支持使用网上公开的无标注的数据进行训练。
模型设计上是基于GPT-1进行改造的,GPT-1的结构是基于Transformer decoder设计的。GPT-2的结构如下:
GPT-2和GPT-1的区别:
GPT-1是(pre-train)预训练+Fine Tuning的训练方式,包括了两个阶段任务(预训练+微调),也就是说为了适应不同的训练任务,模型还是需要在特定任务的数据集上微调,仍然存在较多人工干预的成本;
GPT-2想彻底解决这个问题,通过Zero-shot,在迁移到其他任务上的时候不需要额外的标注数据,也不需要额外的模型训练。GPT-2没有Fine Tuning的过程,直接用训练得到的语言模型用于下游文本生成任务(借助引导符完成)。具体是如何做的,需要进一步思考。GPT-2在GPT的基础上做了微小的修改,其中包括:
第一:LayerNorm的移动和添加;
对于每个子block的输入都加上了layer norm,类似于resnet;
在self-attention的最后也加上了一个额外的layer norm;
Layer Normalization移动到每个sub-block的input;
最后一个self-attention block后面加layer normalization
第二:修改后的残差层的权重初始化策略(每层的初始化权重随层数加深而变小);
residual层的权重初始化乘上了
, 是residual的层数; 在初始化时按
的比例缩放残差层的权重,其中 是残差层的数量; 第三:扩大词表;
词表扩展到了50257个;
Vocabulary扩展到50,257
上下文token数从512调整到1024;
第四:增加context size和batch size;
batch size使用512大小。
更大的batch size(512)。
GPT-2(1.5B parameter Transformer),即使这样,模型仍然没有过拟合WebText,意味着模型的参数可以更多,迁移任务的性能可以进一步提升。对于模型容量的认识,给一个表格:
| BERT | VGG-16 | VGG-19 | ResNet-101 | GPT-2 |
|---|---|---|---|---|
| 3.3亿 | 1.38亿 | 1.44亿 | 0.10亿 | 15.00亿 |
GPT-2的不同网络结构的参数大小如下:
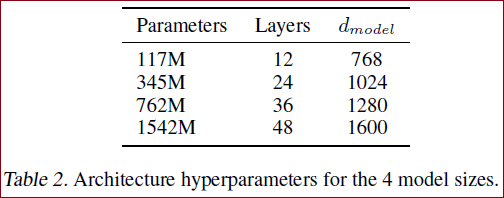
117M(最小模型)是原始GPT模型(GPT-1);
345M是最大的BERT模型(BERT-large);
...
1542M模型(最大的模型)为GPT-2模型。
作者:所有的model,在LM训练的时候,都处于欠拟合的状态。说明他们爬的这个大数据还是很好的!
※ GPT-2是GPT-1的升级版本,其最大的区别在于规模更多,训练数据更多。
GPT-1是12层的transformer,
BERT最深是24层的transformer,
GPT-2则是48层,共有15亿个参数。
※ GPT-2相比于BERT,其并没有采用双向的transformer,依旧采用单向transformer。
GPT-2 采用的 Transformer 的 Decoder 模块堆叠而成,而 BERT 采用的是 Transformer 的 Encoder 模块构建的。
两者一个很关键的区别在于,GPT-2 采用的是传统的语言模型,一次只输出一个单词(多个 token)。
※ 其次,在预训练阶段,GPT-2采用了多任务的方式,不单单只在一个任务上进行学习,而是多个,每一个任务都要保证其损失函数能收敛,不同的任务是共享主体transformer参数的,该方案是借鉴了之前微软的MT-DNN,这样能进一步的提升模型的泛化能力,因此在即使没有fine-turning的情况下依旧有非常不错的表现。
效果上zero-shot不用经过训练和fine-tuning有些也可以达到SOTA:
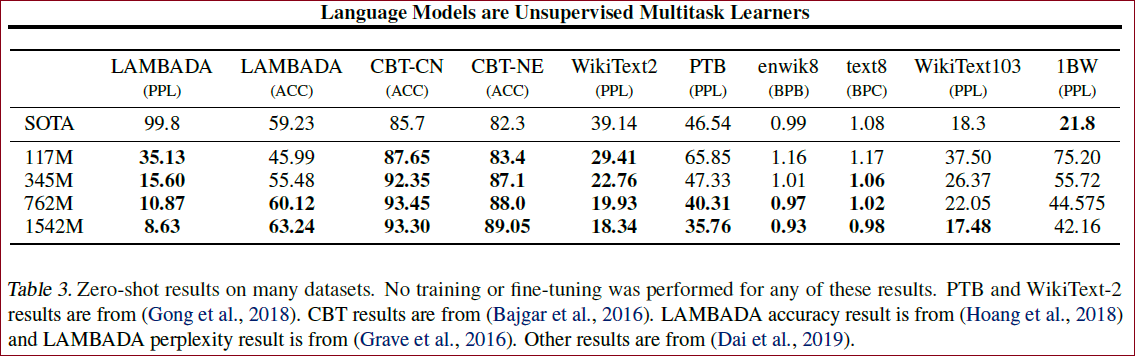
作者直接将这个pretrain的模型,不用finetune的跑了各个下游的NLP任务,即ZSL(Zero-Shot Learning)设定,结果如上。
这里的WikiText2、PTB、enwiki8、text8、WikiText103、1BW是几个测试语言模型的数据集;
LAMBADA是测试建模长句子能力的数据集,用于预测一句话的最后一个词;
CBT是用于检验在不同类型的词上LM的表现,主要是Cloze任务。
分析
可以看到,在Zero-shot的情况下,WebText LMs几乎在所有测试数据集上达到了新的SOTA,除了1BW数据集,语言建模能力惊人。
另外还在很多其他任务上进行了对比实验,大多数也取得了提升,如下图:
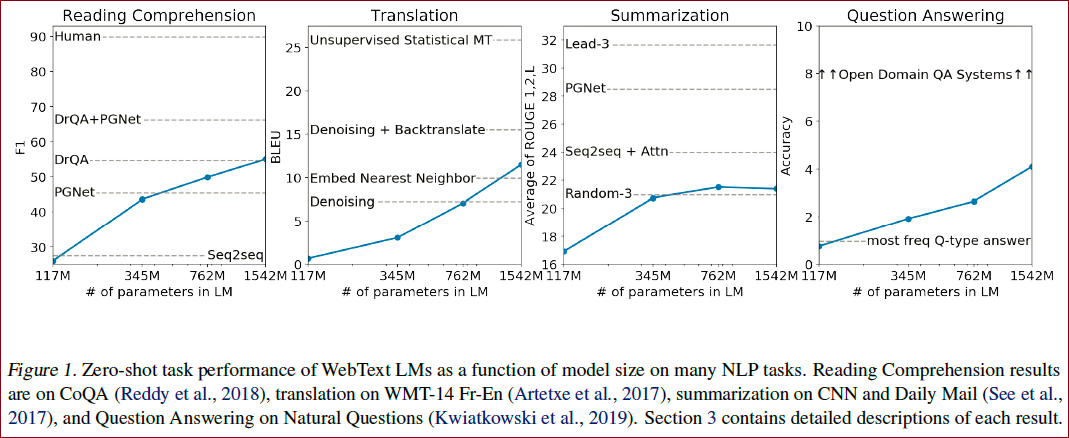
模型框架
GPT-2的核心依旧是语言模型(Language Modeling),语言具有天然的顺序性,通常的形式化可以表示为:
从中可以学习到
单任务预测形式化为
换句表述就是:针对单个任务可以表示为估计一个条件分布:
多任务则为
换句表述就是:对于一个通用的系统来说,可以适用于多种任务:
所以,语言模型也能够学习某些监督学习的任务,并且不需要明确具体的监督符号。
而监督学习由于数据量的关系通常只是无监督学习的一个子集,所以无监督学习的全局最小也必定是监督学习的全局最小,所以目前的问题变成了无监督学习是否能收敛。
博文7 其核心是:多领域文本建模,以实现在不同任务上的迁移。所以model是这样的:
关于零样本学习(zero-shot learning, ZSL)
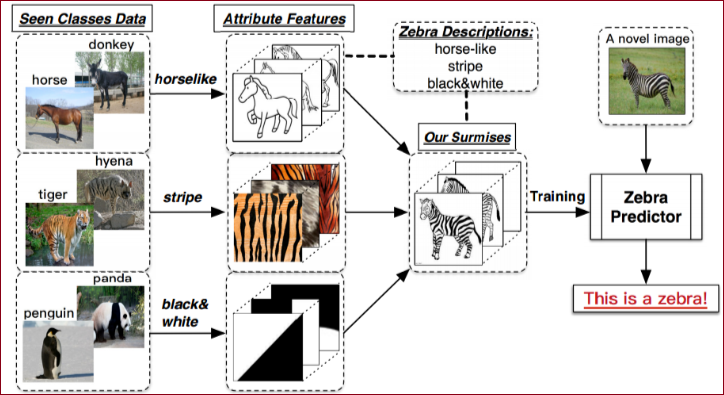
零样本学习通俗来讲:在训练集中并没有出现的
※ 当然,如果不做任何处理我们是无法识别的,我们需要没有出现的
案例 通过上面的图我们可以知道:
horse和donkey可以得出horselike,
tiger和hyena可以得出stripe,
penguin和panda可以得出black and white,
这里我们可以通过zebra的描述信息可以得出horselike,stripe,black and white的动物是斑马来训练模型,这样我们可以在测试集的时候识别出斑马。
引申学习:
方法
语言模型简介
其中
在经过预训练之后,我们在执行特定的任务时,我们需要对特定的输入有特定的输出,这时模型就变成了
为了让模型更一般化,能执行不同的任务,我们需要对模型继续进行处理,变成了
这样一来,我们需要对数据框架的形式进行一定的修改,如翻译任务我们可以写成
translate to french, english text, french text
阅读理解任务可以写成
answer the question, document, question, answer
语言模型在原则上来说是可以利用上面的框架进行无监督学习训练的;
在训练过程中,由于最终的评价方式是一致的,所以监督学习和无监督学习的目标函数是一样的;唯一不同的是监督学习是在子集上进行评估损失,而无监督学习是在全局上评估损失,综合来说对全局不产生影响,因此无监督学习损失的全局最小值和有监督学习损失的全局最小值是一致的;
论文进行初步实验证实,足够多参数的模型能够在这种无监督训练方式中学习,但是学习要比有监督学习收敛要慢得多。
※ 作者认为:对于有足够能力的语言模型来说,模型能够以某种方式识别出语言序列中的任务并且能够很好地执行它,如果语言模型能够做到这一点,那么就是在高效地执行无监督多任务学习。
结果
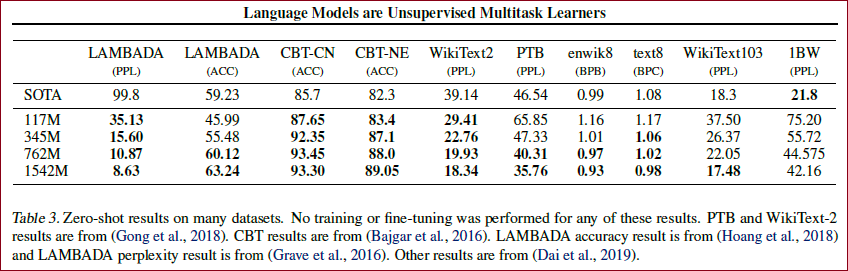
关于指标
这里有
交叉熵(Cross entropy)
这里的
指的是真实概率; 指的是预测概率; 指的是每一个unit;而 由 个unit的 组成,这里表示 这一句话的交叉熵。
也就是一句话出现的概率,句子出现的概率越大,困惑度越小。
其不同就是在计算
即有:
从上表中可以看出,GPT-2都表现出了不错的性能。

同时,在儿童读物测试中,随着参数量的增加,性能都出现了一定的增强。
还有一些结果证实了无标注训练模型的能力,博文1没有展示。
这篇文章证明了当一个大型语言模型在一个足够大和多样化的数据集上进行训练时,它能够在许多领域和数据集上表现良好。
思考
博文2
复现成本极高,几乎意味着不可能。因此期望作者放出预训练的模型,但是作者并没有相关意愿,实际上基于多种语言的预训练模型实用价值更大,在该问题上,BERT做的非常出色,因此可以看到围绕BERT的后续工作也相当的丰富。
作者认为放出预训练模型,会使得模型用于不该使用的地方,比如假新闻的产生等。该理由略显牵强,不做过多讨论,实际上由此引发的一个问题是虚假新闻检测的任务,是一个值得深入挖掘的方向。在CV领域,围绕同质问题的研究已经很丰富了,比如围绕活体检测的一些工作。
不过作者还是放出了一个117M大小的模型,也就是文章中四个模型中最小的。GPT-2大模型和小模型的效果对比参考这里。
适用于基于语言模型的文本生成任务。比如写作助手,围绕该任务,可以基于字、词、句子,甚至段落等粒度。个人认为,当模型用于该任务时,主要得益于数据集(WebText)和大模型(15亿)带来的增益。除此之外,包括对话生成,无监督的机器翻译等。
上文可以看到,常识推理任务表现优秀。或许可以在Kaggle最新的一个比赛Gendered Pronoun Resolution上尝试。
几个角度:
从务实角度出发,个人认为文章的主要贡献在于训练了一个超大容量的语言模型。
从务虚角度出发,文章进一步表明,语言模型和无监督学习在NLP领域的潜力,一个模型解决多个NLP任务是可行的,期待后续相关工作的出现和完善。
从写作上来看,文章的系统性也是非常值得学习的。
比如实验的设计,记忆和泛化的分析方法(通过暴力方式记忆近似全集,如果可以有效解决问题,未尝不可?)等。
GPT-2是一个基于语言建模的文本生成器,由于语言建模本身的通用性,因此它可以提升多个任务。
但是从目前的实验结果来看,有效提升任务类型并不包括诸如机器翻译,文本摘要等任务。
大的数据集和大的模型,由经验结果得到,理应有好的性能提升。这一方面解释了为什么认为媒体对该工作过誉了,另一方面解释了实验结果,它本应如此。
参考博文
[GPT-2]论文解读:Language Models are Unsupervised Multitask Learners
点评:这篇博文说了大概的文章结构和部分重要的概念,但是比较散,需要结合更多的背景知识和原文的细节才能更加理解
[NLP]论文阅读-《Language Models are Unsupervised Multitask Learners》
点评:这篇文章应该是copy别地方的吗?很多图片都失效的。但是有些观点和内容是可以补充的,总体评价★★★☆☆。
GPT2(Language Models are Unsupervised Multitask Learners)论文阅读
★★★☆☆
点评:对一些内容进行了总结,可能想要理解GPT-2就要在GPT-1的基础之上吧,所以本文没写太多,甚至其他参考的文章都没写太多。
论文阅读《Language Models are Unsupervised Multitask Learners》
★★★☆☆
点评:对模型的关键信息进行了总结,但是和前几篇博文内容差不多,作为补充看看吧!
GPT-2 《Language Models are Unsupervised Multitask Learners》解读
★★★☆☆
点评:同上
OpenQA论文阅读(五)GPT-2 Language Models are Unsupervised Multitask Learners
★★★★☆
点评:较前面3篇说的更多,语言更加通俗易懂
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。