Adpter1 - 论文精读学习笔记
Parameter-Efficient Transfer Learning for NLP
标签:Parameter-Efficient Fine-Tuning论文链接:Parameter-Efficient Transfer Learning for NLP | 地址2
官方项目/代码:automl ※ | adapters
发表时间:ICLR 2019
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
全文梗概
※ 一篇 delta tuning 方向的经典论文 Adapter tuning,是一篇比较早的工作,2019 年的 ICML。
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| 大模型微调 | 微调参数不高效或无效 | 提出Adapter模块。基于Bert模型来进行实验,26个不同的分类任务。 | 针对每个任务仅添加少量可训练参数,之前网络的参数固定,参数高度复用。 | 26个分类。包括GLUE benchmark。 | 在训练很少的参数的情况下,可以接近训练全参数的效果。Adapter的GLUE得分为80.0,而完全微调为80.4。 | 模型方法 | PETL, Adapter |
为什么要引入Adapter?
在存在许多下游任务的情况下,微调的参数效率很低:每个任务都需要一个全新的模型。作为替代方案,我们建议使用适配器模块进行传输。
微调大型预训练模型是 NLP 中一种有效的传输机制。 但是如果下游任务太多,就不可能给每一个任务都 fine-tune 再存参数(效率太低了!)这篇论文给出了另外的方案:加一个 adapter 模块。换下游任务的时候只需要调 adapter 里面的参数就可以了,而不是把整个模型里面的参数全给调了。
作者用 BERT 做了 26 个下游任务,跑了 GLUE BENCHMARK.
引入Adapter的目标 对于
论文目标 目标是建立一个在所有这些方面都表现良好的系统,但不需要为每个新任务训练一个全新的模型。
贡献 设计一个有效的适配器模块及其与基础模型的集成。我们提出了一个简单而有效的瓶颈架构。
背景
目前在大规模预训练模型上进行微调是NLP中一种高效的迁移学习方法,但是对于众多的下游任务而言,微调是一种低效的参数更新方式:对于每一个下游任务,都需要去更新语言模型的全部参数,这需要庞大的训练资源。进而,人们会尝试固定预训练模型的大部分参数,针对下游任务只更新一部分参数(大部分情况下都是只更新模型最后几层的参数),但是由于语言模型的不同位置的网络聚焦于不同的特征,针对具体任务中只更新高层网络参数的方式在不少情形遭遇到精度的急剧下降。
从预训练模型的迁移在许多 NLP 任务上产生了强大的性能。
BERT 是一种在具有无监督损失的大型文本语料库上训练的 Transformer 网络,在文本分类和抽取式问答方面取得了SOTA性能
在本文中,我们讨论了在线设置,其中任务以流的形式到达。
目标是建立一个在所有这些方面都表现良好的系统,但无需为每项新任务训练一个全新的模型。
非常重要 任务之间的高度共享对于云服务等应用程序特别有用,在这些应用程序中,需要训练模型来解决客户按顺序到达的许多任务。 为此,我们提出了一种迁移学习策略,可以产生紧凑且可扩展的下游模型。
紧凑模型的意思就是多任务处理的时候换任务只需要换一点参数就可以解决新的task。
可扩展模型是那种可以逐步训练来解决新任务的模型,不会忘记以前的任务。
我们(本文)的方法在不牺牲性能的情况下产出这样的模型。
NLP 中最常见的两种迁移学习技术是基于特征的迁移和微调。 相反,我们提出了一种基于adapter模块的替代传输方法。 基于特征的迁移涉及预训练实值嵌入向量。 这些嵌入可能位于单词、句子或段落级别。 然后将嵌入馈送到自定义下游模型。 微调包括从预先训练的网络复制权重并在下游任务上调整它们。 最近的工作表明,微调通常比基于特征的迁移更好。
基于特征的迁移和微调都需要为每个任务设置一组新的权重。 如果网络的较低层在任务之间共享,则微调的参数效率更高。 然而,我们提出的适配器调整方法的参数效率更高。 Figure 3 左边展示了这种权衡。 x 轴显示每个任务训练的参数数量; 这对应于解决每个额外任务所需的模型大小的边际增加。
从Figure 3 左边可以看到效果:基于适配器的调优比 fine-tuning 训练少两个数量级的参数,同时性能差不多。
Adapters 是加在 pre-trained network 层间的模块。
博文2 作者在标题里用的说法是 parameter-efficient,这个词语碰瓷的是 fine-tune 方法。当时 BERT 刚出不久,基本统治了 NLP 所有任务。然后 pretrain + fine-tune 的 manner 是主流的思路,但这个作者发现:
fine-tune 需要调整所有的参数,对于 N 个任务,最后要存储
fine-tune 需要调整所有参数,对于算力的需求也比较大。
作者想要寻找有没有比 fine-tune 更好的方法,做到:
在下游任务有良好的表现
对于多个任务不用同时需求所有数据集(这个是对比一般的 transfer 方法, 对于多个任务的一般 embedding 需要同时需求所有任务的训练集)
对于每个任务,不需要很多的参数
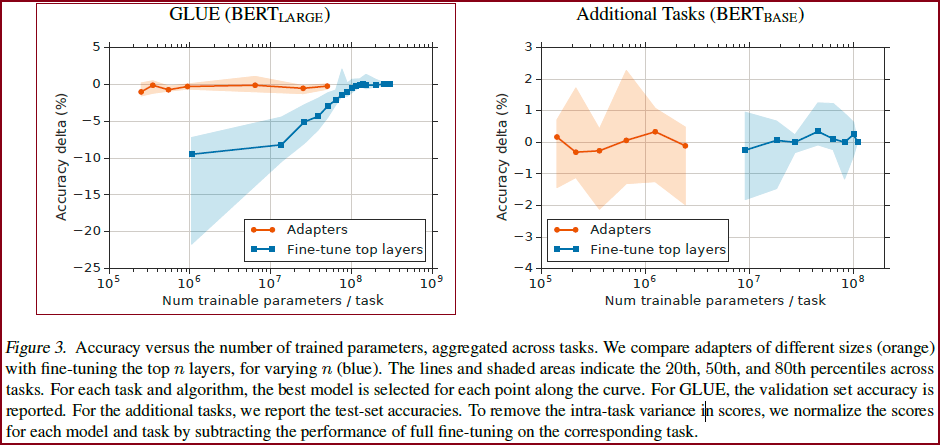
作者想到了 adapter tuning 的方法,只用多训练大约 3% 的参数,就能在 GLUE benchmark 达到正常 BERT 的 99% 的水平,可以说是非常 parameter-efficient 了
Adapter 和 feature-based fine-tuning 的不同
Feature-based 需要弄一个 new function
adapter tuning 只需要 tune
Adapter-based tuning relates to multi-task and continual learning.
Multi-task 可以产生紧凑模型
Multi-task 需要同时访问所有任务(为什么?)而 adapter-based tuning 不需要。
continual learning systems 目标是从一个无限长的任务流中学习。(挑战:网络在 retrain 之后会忘记之前的任务)
adapter-based:任务之间不交互(只有 adapter 部分的参数不一样)其他的共享参数是冻结的。->这意味着该模型使用少量特定于任务的参数对先前的任务具有完美的记忆。
模型方法(核心内容)
本文提出了Adapter,会针对每个下游任务在语言模型的每层Transformer中新增
Transformer的每层网络包含两个主要的子模块,一个attention多头注意力层跟一个feedforward层,这两个子模块后续都紧随一个projection操作,将特征大小映射回原本的输入的维度,然后连同skip connection的结果一同输入layer normalization层。而adapter直接应用到这两个子模块的输出经过projection操作后,并在skip-connection操作之前,进而可以将adapter的输入跟输出保持同样的维度,所以输出结果直接传递到后续的网络层,不需要做更多的修改。每层Transformer都会被插入两个adapter模块。
瓶颈设计

博文5
Adapter的具体结构如图所示。每个 Adapter 模块主要由两个前馈(Feedforward)子层组成,第一个前馈子层(down-project)将Transformer块的输出作为输入,将原始输入维度
(高维特征)投影到 (低维特征),通过控制 的大小来限制Adapter模块的参数量,通常情况下, 。然后,中间通过一个非线形层。在输出阶段,通过第二个前馈子层(up-project)还原输入维度,将 (低维特征)重新映射回 (原来的高维特征),作为Adapter模块的输出。同时,通过一个skip connection来将Adapter的输入重新加到最终的输出中去,这样可以保证即便 Adapter 一开始的参数初始化接近0,也由于skip connection的设置而接近于一个恒等映射,从而确保训练的有效性。 博文3
上图显示了我们的适配器体系结构,以及它在Transformer的应用。Transformer的每一层都包含两个主要子层:注意层和前馈层。
左图:将适配器模块两次添加到每个Transformer层,在多头注意之后的投影和两个前馈层之后。
右图:适配器由瓶颈组成,瓶颈包含与原始模型中的注意力和前馈层相关的几个参数。
适配器还包含一个跳过连接。在适配器调优期间,绿色层在下游数据上进行训练,这包括适配器、层归一化参数和最终分类层。
为了限制参数的数量,提出了一个瓶颈架构。适配器首先将原始的d维特征投影到较小的维度m中,使用非线性,然后投影回d维。每层添加的参数总数(包括偏差)为2md + d + m。通过设置m 远小于 d(
),我们限制了每个任务添加的参数数量。 为了实现这个特性,我们提出了一个 bottleneck adapter module. 用 adapter 做 tuning 需要向模型里放一点新参数,这些新参数在下游任务里面训练。
在对深度网络进行 vanilla 微调时,会对网络的顶层进行修改。
这是必需的,因为上游和下游任务的标签空间和损失不同。
※ adapter module 执行更通用的架构修改,以将预先训练的网络重新用于下游任务。 具体来说呢,adapter module 调整涉及将新层注入原始网络。 原始网络的权重保持不变,而新的adapter module层的权重是随机初始化的。正常 fine-tuning中,新的顶层和原始权重是共同训练的。 而在adapter module调整中,原始网络的参数被冻结,因此可能被许多任务共享。
※ Adapter Module 的两个特点:参数少 和 near-identity initialization。
※ Adapter Module 需要做得很小,这样总模型大小随着 task 增多不会增加太快。
near-identity initialization 是为了模型魔改后还能稳定训练,同时训练开始的时候原网络不受影响。训练的时候 adapter 才会被激活,进而影响整个网络的激活分布。如果你用不到 adapter 也可以直接 ignore 它们。(感觉有点像 plug-in)
在第 3.6 节中,我们观察到一些特定的adapter对网络的影响比其他adapter更大。 我们还观察到,如果初始化偏离恒等函数太远,模型可能无法训练。
博文4 Instantiation for Transformer Networks
我们在 text Transformers 上操作一下 adapter-based tuning. Transformers 在很多领域都是 SOTA 级别。
这篇论文在 2017 年的 standard Transformer 上做了实例化(博文4作者的blog中有?没找到呢~)。
adapter 的架构很多,这篇论文弄了一个比较简单的设计,还试了下更复杂的设计,但最后实验发现效果都差不多。
Figure 2 就是我们的 adapter 架构,和加了 adapter 的 transformer 架构。
Transformer 的每一层都包含两个主要的子层:注意力层和前馈层。 两个层后面紧跟着一个投影,将特征大小映射回层输入的大小。
跳过连接(skip-connection)应用于每个子层。
每个子层的输出被送入Layer Norm。
我们在每个子层之后插入两个串行adapter。
适配器总是直接应用于子层的输出,在投影回输入大小之后,但在添加回跳跃连接之前。 然后将适配器的输出直接传递到下一层规范化。
看下Figure 2 的右边部分。为了限制参数的数量,我们提出了一个瓶颈架构。
1 adapter 首先将原始 d 维特征投影到较小的维度 m,应用非线性(nonlinearity),2 然后再投影回 d 维度。 每层添加的参数总数(包括偏差)为 2md + d + m(这玩意咋算的?)。 通过设置
,我们限制了每个任务添加的参数数量; 在实践中,我们使用了大约 0.5 - 8% 的原始模型参数。 瓶颈维度 m 提供了一种简单的方法来权衡性能与参数效率。
adapter 模块本身在内部具有跳过连接。 使用跳跃连接,如果投影层的参数被初始化为接近零,则模块被初始化为近似恒等函数。
除了适配器模块中的层,我们还为每个任务训练新的层规范化参数。 这种技术类似于条件批量标准化 (De Vries et al., 2017)、FiLM (Perez et al., 2018) 和自调制 (Chen et al., 2019),也产生了参数有效适应 一个网络; 每层只有 2d 个参数。 然而,单独训练层归一化参数不足以获得良好的性能,请参见第 3.4 节。
Adapter的作用和优势很多,方法却非常简单。在这里,作者一般性的考虑了Transformer block!
对于一般的 transformer block 一般是前面是一个 self-attention/cross-attention,加一个 feed-forward,然后是一个残差链接,接着一个 layerNorm,再接一个 feed-forward,然后是一个残差链接,接 layerNorm
作者在这个过程中间插入了一些小的 Adapter 层,在训练中只有绿色的部分是可训练的,别的部分的参数被锁定(BERT 的预训练参数)。
实现中和设计中有几个很重要的细节:
插入的 adapter 层在 feed-forward 后面,在残差链接前面,因此不影响 transformer block 残差链接在深度上的的效果;
adapter 层本身是含有 skip-connection 的,因此全 0 初始化的 adapter 层对 transformer block 来说相当于不变。这一点很重要,因为训练的初期模型相当于和原模型保持一致,对训练的稳定性非常重要。
作者在训练中让 transformer bolck 的 layerNorm 层是不锁参的 (用的 pair-wise muliply norm),这样的好处是:对于 adapter 层来说,为了减小参数量,用了所谓的 feed-forward-down 和 feed-forward-up 方法,使得中间变量的维度变得很小,SiLu 激活函数连接。
作者提到,还有另外一些 adapter 层的设计方法,和这种设计方法的表现十分接近,本文就强调了这种设计,其他的设计还类似于:
adding a batch/layer normalization to the adapter
increasing the number of layers per adapter
different activation functions, such as
inserting adapters only inside the attention layer
adding adapters in parallel to the main layers, and possibly with a multi- plicative interaction.
总体而言,这边文章的关键不在 adapter 具体的设计,而在于这种方法本身,parameter-efficient 训练,或者现在叫 delta tuning 方法的灵感。
Adapter 与 Transformer的结合框架。
在Transformer中的两个地方增加,一个地方在projection后面,一个地方在两个前向层后面;
对于每个Adapter层像一个瓶颈。它的参数比较原始模型少很多,也包含skip-connection,只更新绿色部分内容。
实验与分析
以构建Bert模型为例,模型基本继承,包含关系如下图所示
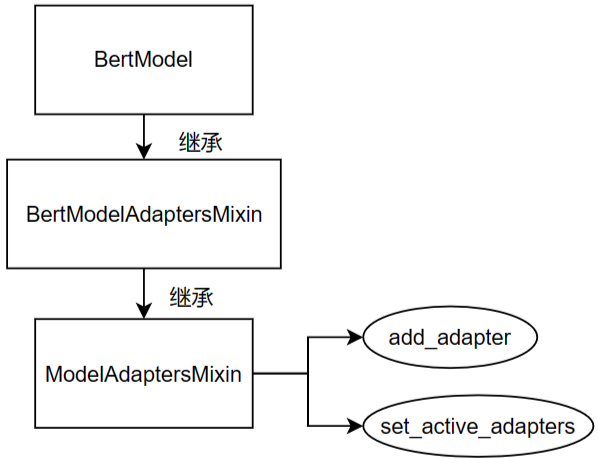
部分代码细节,可以参考博文3中的Section 三。
AutoML平台 | Github-AutoML平台 进行实验的(这个平台值得深入看看)。
博文2 这篇论文的实验设计其实还挺好的,作者在包括 GLUE benchmark 在内的多个任务中,用 BERT 作为锁参的“大模型”来对比正常的 BERT fine-tune, Variable fine-tune 和非 BERT SOTA 的结果:
博文4 下面展示 Adapter 做到了在文本任务上 parameter efficient transfer。
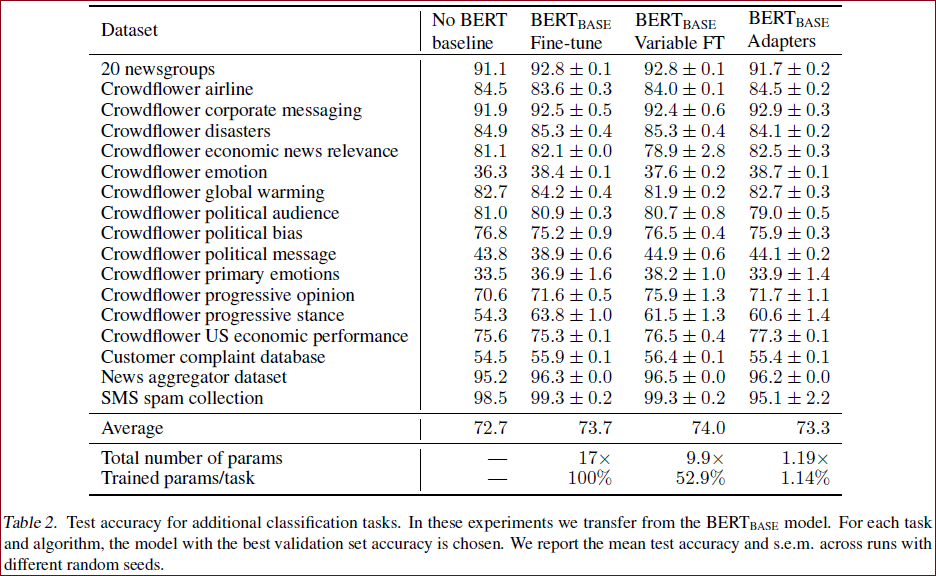
作者行文用了很多的数据来表示:adapter 方法和 fine-tune 基本没有任何区别,效果只下降了一点点点点。
对比实验
在这一部分,作者对 adapter 训练方法的特性做了很多的探索,可以引发人非常多的思考,同时这一部分的实验设计更是非常巧妙:
移除 adapter
虽然每个适配器对整体网络的影响很小,但整体效果很大。
正常 adapter 是在每一层都有的,作者试着单独一处某一层的、或者移除一些层的 adapter 看效果:
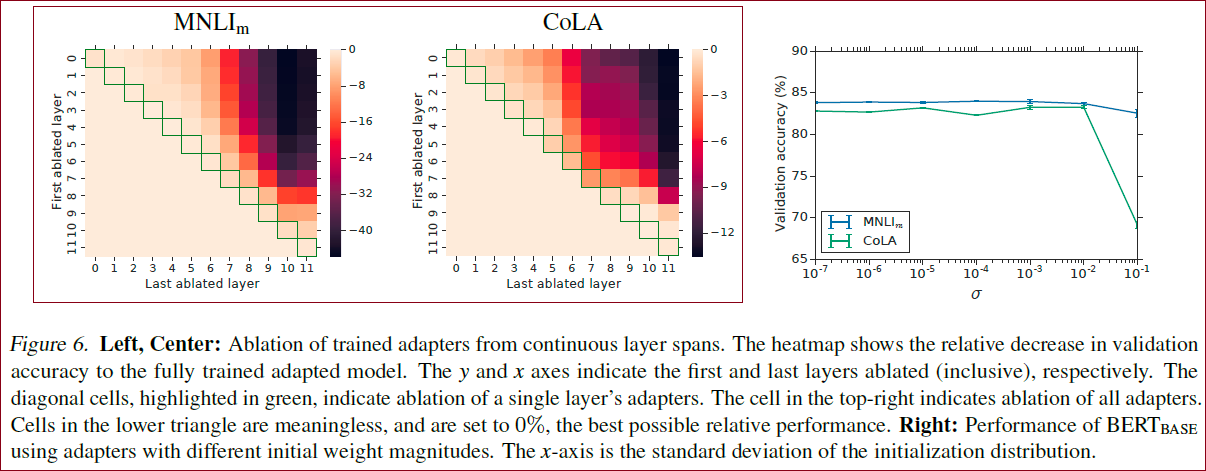
如Figure 6 中的这个热力图的横纵坐标的跨度对应的层的 adapter 被移除了,对角线代表只移除一个 adapter,右上角代表所有的都移除。这个图其实很有意思:
对角线的表现基本没有下滑,这代表单独一层的 adapter 其实没有起什么作用,也就是说 adapter 层的参数和全 0 没啥区别。另一点上,对角线右下角 (上层) 的表现下降更多一些,说明上层的 layer 对模型的表现更重要
这一点有些佐证了” 大模型前面层表征通用知识,后面层表征细粒度知识 “的论点,因为后面的 adapter 对下游任务的帮助更大。
当移除的数量增大时,表现下滑的很快,这说明 adapter 层其实是共同起作用的,并且起的作用各不相同。这其实正可以说明 adapter 层是非常 parameter-efficient 的了
鲁棒性
如Figure 6 中的Right图,作者在这里探索了 adapter 层参数的表示是不是鲁棒的,也就是把正常训好的 adapter 参数叠加一个高斯噪声。
※ 当高斯噪声不大时 (
另一方面,作者探索了 adapter 层参数对表现的影响:其实用比较小的 adapter 就能达到差不多的表现。这个论点也许可以用 intrinsic dimension 的角度衡量,后面我博文2也许会写论文阅读笔记。
较低层上的适配器比较高层上的适配器影响较小。
在两个数据集上,适配器的性能对于低于10−2的标准差是鲁棒的。但是,当初始化太大时,性能会下降,对CoLA的影响更大。
跨适配器大小的模型质量是稳定的,并且在所有任务中使用固定的适配器大小可以对性能造成很小的损害。
以下扩展未能显著提升性能
(i) 向适配器添加批处理/层规范化,
(ii) 增加每个适配器的层数,
(iii) 不同的激活函数,例如tanh,
(iv) 仅在注意层内插入适配器,
(v) 与主层并行添加适配器,并可能使用乘法交互。
数据集
GLUE benchmark
GLUE benchmark的结果
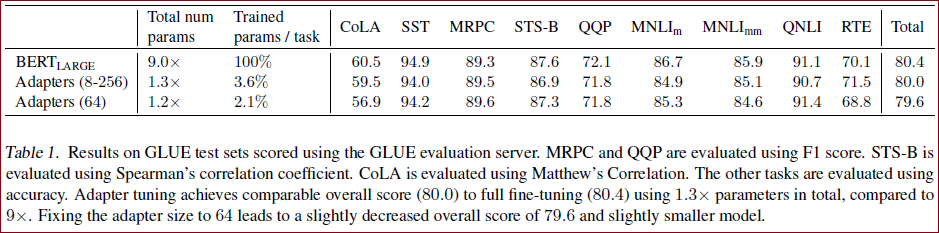
GLUE得分为80.0,而完全微调为80.4;
BERT_LARGE模型的总调参数为9.0 x,表示这9个任务都得微调的总和;
Adapters的最好效果为80.0,而参数总量只为1.3倍于原模型参数据,训练的参数只有3.6%。
17个公开数据
SQuAD question answering
通过实验发现,只训练少量参数的Adapter方法的效果可以媲美全量微调,这也验证了Adapter是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。
Adapter 最佳的中间层特征维度
总结
博文1 提出了与Transformer相结合的adapter模型,可以在训练少参数的情况下达到全调的效果。想法很不错,效果也是比较好的。
补充
博文3
总体而言,作者在 pre-train 刚出半年多,就想到、对比了 fine-tune manner,可见科研思路的敏锐。
同时,作者的 adapter 主打小参数,因此设计的一些鲁棒性方面的附加实验也非常好
既然通过给 basebone 模型添加一些参数,可以实现媲美 fine-tune 的效果;那么只训练 basebone 模型的一点参数,或者把运算方式进行一些改变,能不能获得媲美 fine-tune 的效果呢?
参考博文
[论文阅读72]Parameter-Efficient Transfer Learning for NLP
点评:★★★☆☆, 内容不多,但是基本的了解是大概够的。
论文阅读 [精读]-Parameter-Efficient Transfer Learning for NLP
点评:★★★★☆,有自己的思考,也对一些内容进行了补充。
【论文解读】Parameter-Efficient Transfer Learning for NLP
点评:★★★★☆,语言通俗易懂,是个不错的文章。
Paper Reading - [ICLR 2019] Parameter-Efficient Transfer Learning for NLP
点评:★★★★☆,这篇博文的语言也很通俗,这种博文都是很棒的!!
Parameter-Efficient Transfer Learning for NLP
点评:★★★☆☆,这个博主主要写的都是梗概且重要的文章,能帮助理解大致的内容,还是很棒的,因为内容比较少,所以没有给很高的评分,这不代表博主的内容不好哦~ 。
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。