GPT31 - 论文精读学习笔记
Language Models are Few-Shot Learners
Basic Architectures of LLMs
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
官方项目
模型未开源,人造数据集
地址:https://github.com/openai/gpt-3/tree/master
说明:博文7 GPT-3没有开源,只能通过API调用。OpenAI官方没有明确说现在哪些API是GPT-3的,我猜测https://platform.openai.com/docs/models/gpt-base这两个文本生成模型应该是GPT-3的,但是官方也不建议继续使用GPT-3的API了,建议大家用3.5和4。因此GPT-3的主要价值就是承前启后、了解GPT系列模型的发展史了。
背景
OpenAI在18年、19年、20年接连发布了GPT三部曲,其模型分别被称为GPT-1、GPT-2和GPT-3。
OpenAI GPT-1, GPT-2, GPT-3
Google BERT
GPT-1 其中GPT-1借鉴CV领域的预训练思路,基于Transformer模型的解码器,实现了利用无标签文本预训练再有监督微调以适应下游子任务的语言模型,并在9个子任务上取得最佳得分。
Google - BERT 也许是受其(GPT-1)启发,Google的团队随即发布了BERT与之针锋相对,BERT使用了Transformer的编码器,并增大了预训练数据集,效果也比GPT-1好。
GPT-2 OpenAI在次年继续改进,然而模型结构并无太大变化,且继续增大数据集并没有让精度起飞,效果并不显著。于是GPT-2的文章找了个偏僻的角度看问题,从多任务学习和零样本学习发力,这个方向的其它方案自然比不过砸海量预训练数据的GPT-2了。而从GPT-2开始不再进行有监督微调而强调零样本。
GPT-3 而20年的GPT-3,也就是本篇论文,其模型方面与GPT-2一致,通篇都在讲结果、讨论,都是各种各样的分析,而其关键的训练部分比较模糊。
GPT-3 vs GPT-2
GPT-3在效果上超出GPT-2非常多,能生成人类难以区分的新闻文章;
GPT-3主推few-shot,相比于GPT-2的zero-shot,具有很强的创新性;
GPT-3模型结构略微变化,采用sparse Attention模块;
GPT-3海量训练语料:45TB(清洗后570GB),相比于GPT-2的40GB;
GPT-3海量模型参数,最大模型为1750亿,GPT-2最大为15亿参数。
GPT-1, GPT-2, GPT-3模型参量对比:
GPT-1 110M 2018年
GPT-2 1.5B 2019年
GPT-3 175B 2020年
最近几年语言模型在NLP任务中应用广泛,通常需要在特定任务的数据集上进行微调,而参数巨大的模型在微调时存在较大代价。本文提出使用大模型预训练语言模型,在推理时进行少样本学习,以适应不同任务,减少对特定任务数据集的依赖。
Pre-training和fine-tuning架构存在的问题:
对于每个新的任务,都需要大量的标注数据;
博文2对这个内容的进一步阐述:
提出问题
最近的许多研究都表明pre-train模型搭配下游任务fine-tune在许多情况下效果显著,但是微调过程需要大量的样本。这一框架不符合人类的习惯,人类只需要少量的示例或说明便能适应一个新的NLP下游任务。
许多基于RNN或Transformer结构的语言模型通过“pre-train + fine-tune”过程在阅读理解、问答系统等任务中有不俗的性能。然而本文认为上述架构最大的问题在于必须拥有大量的下游任务fine-tune样本才能取得很好的性能。因此,本文基于下述原因认为移除fine-tune是必要的:
每一个新的任务都需要大量的标记数据不利于语言模型的应用的;
提升模型表征能力的同时降低数据分布的复杂度是不合理的;
e.g., 大模型并不能在样本外推预测时具有好效果,这说明fine-tune导致模型的泛化性降低了。
人类在接触一个下游语言任务时不需要大量的样本,只需要一句对新任务的描述或者几个案例。人类这种无缝融合和切换多个任务的能力是我们当前自然语言技术所欠缺的。
解决方案
模型移除fine-tune有2个解决方案
meta-learning
模型在训练阶段具备了一系列模式识别的能力和方法,并通过在预测过程中利用这些能力和方法以快速适应一个下游任务。最近的一些研究尝试通过称为
in-context learning的方法来实现上述过程,然而效果距离期待的相差甚远。Large scale Transformer
Transformer语言模型参数的每一次增大都会让文本理解能力和其他的NLP下游任务的性能得到提升。
此外,有研究指出描述许多下游任务性能的log损失能让模型的性能和参数之间服从一个平滑趋势。考虑到
in-context learning会将学习到的知识和方法存在模型的参数中,本文假设:模型的情境学习能力也会随着参数规模的增大而增长。
将表达能力更强的模型(预训练阶段要求用大模型)在比较窄的数据(微调阶段是在narrow数据分布上进行的)上训练是不合理的。
大模型的效果并不能泛化到OOD数据上。
人类在接触一个下游任务时不需要大量的训练样本,只需要对任务的描述或者几个例子就可以。
我们希望NLP模型也能有这种多任务之间无缝衔接的能力。
梗概
博文7 GPT-3的框架跟GPT-1、2的差不多,但是扩大了网络参数规模,使用了更多的高质量训练数据,就使得其模型效果实现了显著提升,可以不用微调,直接通过少样本学习/上下文学习的方式,在prompt中给出任务示例,就能在新的预测样例上得到想要的结果。有些少样本学习效果比微调的SOTA模型还好。
本文没有做GPT-3微调效果的实验。
————————————————
主要贡献 本文证明了通过增大参数量就能让语言模型显著提高下游任务在Few-Shot(仅给定任务说明和少量示例)设置下的性能。
博文2作者: 证明了大规模语言模型使用元学习策略的可能 & fine-tune策略的非必要性。
具体贡献
训练了包含175 billion参数(以往非稀疏语言模型的10倍大小)的GPT-3自回归语言模型,并在多个数据集上测试没有fine-tuning过程中的性能表现;
GPT-3也是一个自回归语言模型,但参数量更大,具有175B参数量,是GPT-2的117倍,大力出奇迹。
虽然GPT3在文本翻译、问答系统、完形填空、新词使用和代数运算等任务表现不错,但在阅读理解和推理任务数据集上的表现仍有待提高;
由于GPT3的训练依赖于大量的网页语料,所以模型在部分测试数据集上可能出现方法论级别的data contamination问题;
GPT3能够编写出人类难以区分的新闻文章,本文讨论了该能力的社会影响力。
作者在大量的NLP任务上进行实验,通过实验发现预训练后没有微调的GPT-3可以达到甚至超过经过微调的BERT模型的实验结果。
论文训练了一个175B的模型GPT-3,在3种设定下测试GPT-3的性能:
few-shot learning(in-context learning):允许一些样例(一般10到100个)出现在模型输入中
one-shot learning:只允许一个样例
zero-shot learning:不允许提供样例,只提供一个自然语言形式的指令。
下图展示了在移除单词中多余符号任务上,模型的表现:
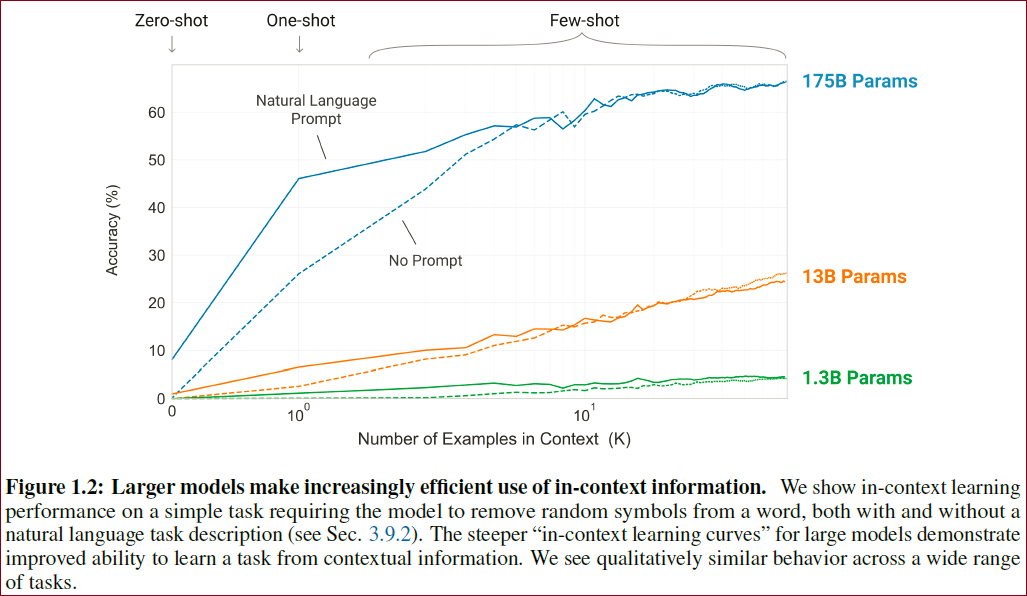
GPT-3在zero-shot和one-shot设置下能取得不错的结果,在few-shot设定下有时能比得上甚至超过微调的SOTA模型
zero-shot和one-shot设置的GPT-3能在快速适应和即时推理任务(单词调整、代数运算和利用只出现一次的单词)中拥有卓越表现;
few-shot设定下,GPT-3能生成人类难以区分的新闻稿;
few-shot设定下,GPT-3在一些自然语言推理任务(ANLI dataset),阅读理解(RACE, QuAC)上的性能有待提高;
不同benchmark上的整体表现如下图所示:
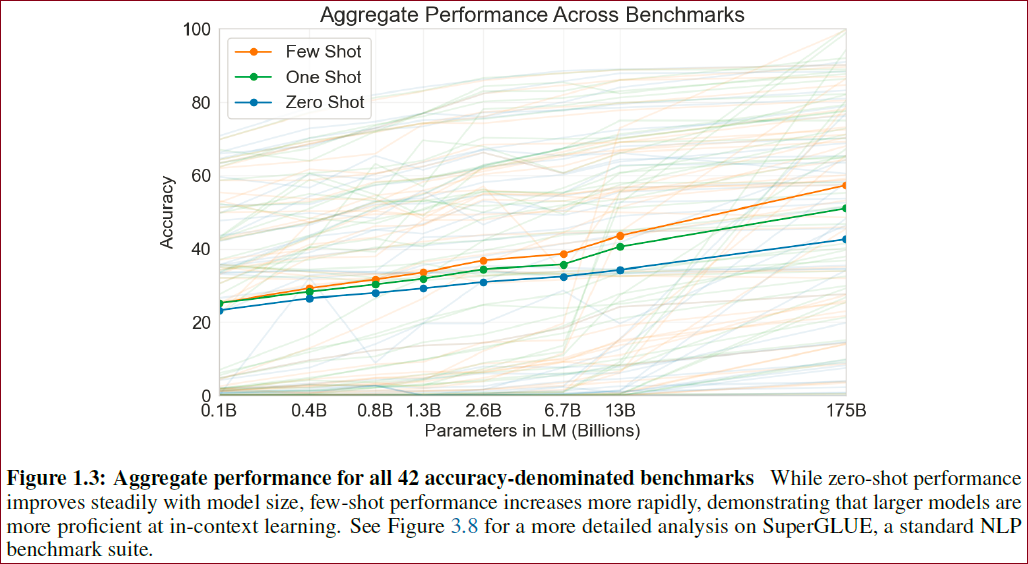
文章还训练一些小模型(从125 million 到 13 billion),用于和GPT-3对比。
对于大多数任务,在3种设定下,模型性能随大小相对平滑地增加。
但是随着模型容量增大,few-shot相较于one,zero-shot的领先幅度变得更大,这说明大模型可能更适合作为meta-learners(larger model are more proficient meta-learners)。
概念
情境学习(in-context learning) - 上下文学习
优势:
不用大规模微调数据集。
效果随模型尺寸增长而编号(但是不如微调)。
而且模型不会产生微调导致的分布局限问题,在通用任务上表现能力不会下降。
哦?微调会产生问题的吗?额外收获!
在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测以补全任务中其他的实例。即,情境学习要求预训练模型要对任务本身进行理解。情境学习三种分类的定义和示例如下:
few-shot learning
定义:允许输入数条范例和一则任务说明
示例:向模型输入“这个任务要求将中文翻译为英文。你好->hello,再见->goodbye,购买->purchase,销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
one-shot learning
定义:只允许输入一条范例和一则说明任务
示例:向模型输入“这个任务要求将中文翻译为英文。你好->hello,销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
zero-shot learning
定义:不允许输入任何范例,只允许输入一则任务说明
示例:向模型输入“这个任务要求将中文翻译为英文。销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
few-shot相比于zero-shot为什么更有效?
在few-shot给的几个样例在新任务时会作为条件输入,相当于模型拥有了该任务更多的先验知识。
sparse attention
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个token之间两两计算attention,复杂度为
; sparse attention:每个token只与其他token的一个子集计算attention,复杂度为
具体来说:
sparse attention除了相对距离不超过k以及相对距离为k, 2k, 3k, ... 的token,其他所有token的注意力都设为0,如下图所示:
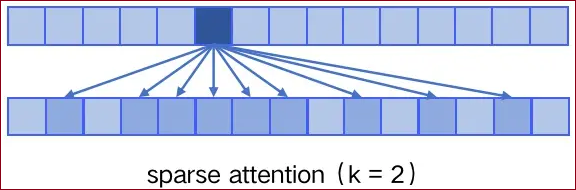
使用sparse attention的好处(主要有2点):
1 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
2 具有“局部紧密相关和远程稀疏相关”的特性:对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
本文研究内容
本文训练了一个拥有175 billion参数的自回归语言模型(GPT-3),并利用两组NLP数据集和一些全新的数据集评估了模型的情境学习能力和快速适应新任务能力。
对于每一个任务,作者都测试了模型“few-shot learning”, “one-shot learning” 和 “zero-shot learning”三种条件的性能。虽然GPT-3也支持fine-tune过程,但文本并未测试。
关于GPT-3的研究结果
整体上,GPT-3在zero-shot或one-shot设置下能取得尚可的成绩,在few-shot设置下有可能超越基于fine-tune的SOTA模型。
zero-shot和one-shot设置的GPT-3能在快速适应和即时推理任务(单词整理、代数运算和利用只出现过一次的单词)中拥有卓越表现。
few-shot设置的GPT-3能够生成人类难以区分的新闻文章。
通常不同参数的模型在三种条件(zero-shot, one-shot, few-shot)下的性能差异变化较为平稳的,但是参数较多的模型在三种条件下的性能差异较为显著。本文猜测:大模型更适合于使用“元学习”框架。
本文发现few-shot设置的模型在自然语言推理任务(如ANLI数据集)上和机器阅读理解(如RACE或QuAC数据集)的性能有待提高。未来的研究可以聚焦于语言模型的few-shot learning部分,并关注哪些发展是最需要的。
关于data contamination的研究结果
问题定义:因为高性能模型的训练依赖于大量的网页语料如Common Crawl数据集,所以测试集中的语料可能由于已经在网页中出现过而在训练集中被模型看到过。
解决方案:本文提出了一个系统化的工具来衡量data contamination情况并量化它的影响。
解决Pre-training和fine-tuning架构存在的问题的可行的方案
meta-learning
模型在预训练阶段就学到了一系列方法,具备一系列能力。
在预测阶段,我们利用这种能力来快速适配到下游任务中。
已经有人通过in-context learning这样做过了,但是效果不好。
在GPT-3中使用了跟GPT-2一样的方式,这里称为
in-context learning(也就是Prompt,通过加上了上下文信息来做任务的自动区分);模型在无监督学习下会有识别不同类型范式(pattern)的能力。类似下图中有三种不同类别的sequence范式,样本中识别完类别后相当于进行该范式的循环学习。
在非监督预训练期间,语言模型积累了大量的模式识别能力,并将这些能力用在推理过程中,以求快速适应新的任务。我们用“in-context learning”来描述这个过程中的inner loop,这些inner loop发生在每个序列的正向传递中。
下图告诉我们许多时候单一的序列中重复包含多个子任务的嵌入。
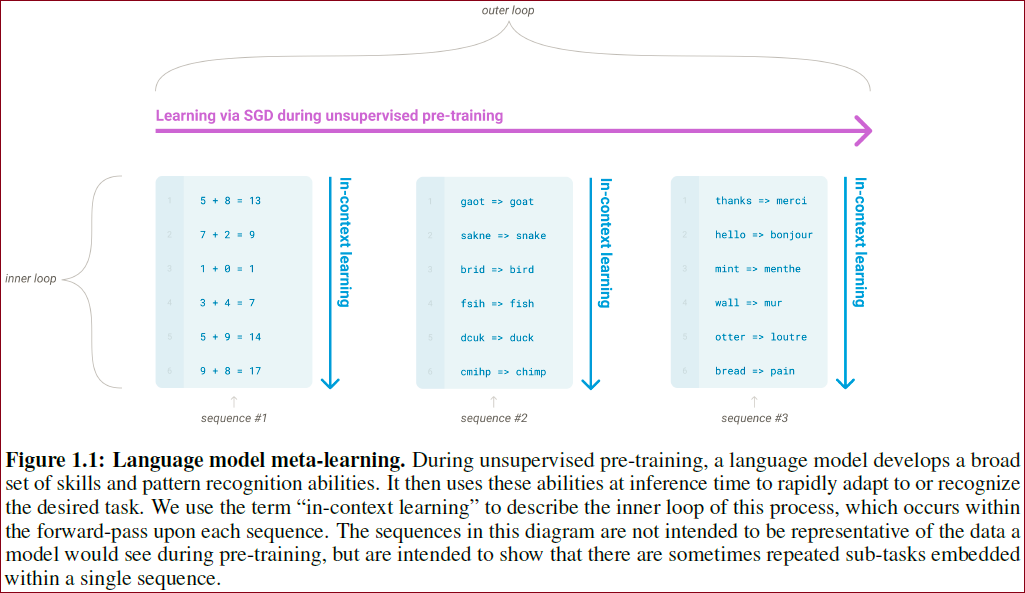
语言学习的meta-learning过程
LLM
Transformer语言模型参数的每一次增大都会让文本理解能力和其他NLP下游任务的性能得到提升,而且有证据显示:log损失函数,在模型规划增大后,保持平稳趋势。
前人的工作已经证明了log loss随模型变大而下降,交叉熵损失下降也会带来在下游任务上效果的提升。
我们认为:in-context learning的能力也会随着模型参数的增大而增强。
测试发现当模型越大对于测试的zero-shot/one-shot/few-shot相关的效果越好。
更大的模型拥有更强的利用情境信息能力
我们定义了一个简单的任务,要求模型移除一个单词中的随机符号。
图1.2展示了模型在给定或未给定一段文本形式的任务描述下的情境学习性能。
那根陡峭的蓝色线告诉我们从环境信息中学习任务的能力。不仅在图1.2中明显可以看出模型的性能随着增加文本形式的任务描述或者增加模型参数而增加,模型性能和模型尺寸与情境样本数关系的趋势在许多其他的任务中都有体现。作者特别强调这几根数据线与fine-tune无任何关系,仅仅将增加示例数量作为限制条件。
图1.3:聚合了模型在42个基准数据集上的性能
因为zero-shot设置下的模型性能随着模型参数的增加稳定上升,few-shot设置下的模型性能随着模型参数的增加急剧下降,所以本文认为大模型适合情境学习。
方法
博文4
训练了8个不同大小的Transformer(解码器部分)语言模型,最大的包含1750亿参数(称为GPT-3);
在无监督大规模文本数据集上进行预训练;
在推理时,使用0样本(只描述任务)、1样本或少量样本(10-100个)作为任务实例,进行零样本、一样本和少样本学习;
分布式训练、模型分割、数据分割;
训练数据集从各个数据集(含Reddit数据集)进行采样,对较为低质量的Common Crawl进行权重控制,并用LSH算法做文章去重;
GPT-3在应用到子任务时不做任何梯度更新或是微调,主打上下文学习能力。
本文的预训练方式GPT-2类似,只不过用了更大的模型,数据量,多样性以及训练时长,in-context learning的方式也相似。
本文的实现与GPT-2的方法相似,预训练过程的不同只在于采用了参数更多的模型、更丰富的数据集和更长的训练的过程。本文聚焦于系统分析同一下游任务不同设置情况下,模型情境学习能力的差异。下游任务的设置有4类。
不过本文系统分析了不同设置对利用上下文学习的影响,这些设置可以看作对任务相关数据的依赖程度。
Fine-tuning(FT):本文并没有训练GPT-3的微调版本,因为主要关注的是task-agnostic性能;
FT利用成千上万的下游任务标注数据来更新预训练模型中的权重以获得强大的性能。但是,该方法1 不仅导致每个新的下游任务都需要大量的标注语料,2 还导致模型在样本外预测的能力很弱。虽然GPT-3从理论上支持FT,但本文没这么做。
Few-shot(FS):在预测阶段提供一些样本,但并不进行参数更新。样本的数量是10到100(window size内可容纳的样本数目)
模型在推理阶段可以得到少量的下游任务示例作为限制条件,但是不允许更新预训练模型中的权重。
FS过程的示例可以看本笔记图2.1点整理的案例。
FS的主要优点是并不需要大量的下游任务数据,同时也防止了模型在fine-tune阶段的过拟合。
FS的主要缺点是不仅与fine-tune的SOTA模型性能差距较大且仍需要少量的下游任务数据。
One-shot(1S):仅提供一个样本;
模型在推理阶段,仅得到1个下游任务示例。
把1S独立于few-shot和zero-shot讨论是因为这种方式与人类沟通的方式最相似。
Zero-shot(0S):不提供样本,只给一个用于描述任务的自然语言指令。
模型在推理阶段仅得到一段以自然语言描述的下游任务说明。
0S的优点是提供了最大程度的方便性、尽可能大的鲁棒性并尽可能避免了伪相关性。
0S的方式是非常具有挑战的,即使是人类有时候也难以仅依赖任务描述而没有示例的情况下理解一个任务。
但毫无疑问,0S设置下的性能是最与人类的水平具有可比性的。
GPT-3评测特点 GPT-3在评测过程中没有进行finetune,也就是没有相关的gradient梯度更新。只用到了zero-shot、one-shot、few-shot分别对应在推理时的上下文中增加的prompt样本个数。
下图是一个将英文翻译成法语任务的不同设定下的输入形式展示:

图2.1 Zero-shot, One-shot, Few-shot和Fine-tuning之间的比较
图2.1以英文发育互译作为示例来显示了四种下游任务设置的区别通常,预训练模型对于不同的任务会进行微调,微调过程如下(以机器翻译为例):

而作者应用GPT-3模型并没有微调,而是尝试了三种任务:
1 zero-shot:输入问题描述,输出答案;
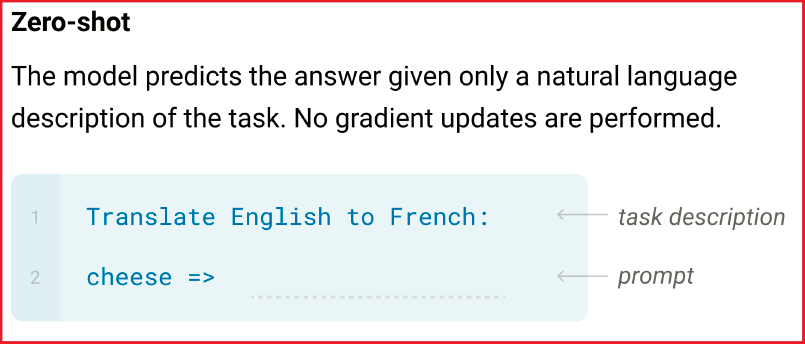
图2.1(分离)
2 one-shot:输入一个问题和答案的例子,再输入一个问题,输出答案;

图2.1(分离)
3 few-shot:输入一些问题和答案的例子,再输入一个问题,输出答案;

图2.1(分离)
本文的不同设定并不是为了相互比较、相互替代。而是在特定基准上,提供性能与采样效率之间权衡的不同问题设定。
模型和架构
整体结构和GPT-2一样,但不同的是采用了类似Sparse Transformer的Sparse attention,如原文表2.1,测试了不同超参的GPT-3模型。
模型结构,初始化方法,预归一化方法(预标准化方法),tokenize方法(分词方法)与GPT-2完全一致,但在Dense层和Locally Banded Sparse Attention层借鉴Sparse Transformer。
为了探究机器学习性能和模型参数的关系,我们分别训练了包含1.25亿至1750亿参数的8个模型,并把1750亿参数的模型命名为GPT-3。
训练了8个不同大小的Transformer(解码器部分)语言模型,最大的包含1750亿参数(称为GPT-3)。
作者训练了一个非常大的预训练语言模型GPT-3。其最大参数量可达1750亿。模型继承了GPT-2的结构,使用了更深的层数和更多的自注意力头数。
不同模型参数设定如下表所示:
每列含义
模型名称 | 参数数量 | 模型层数*维度 | 多头数量*维度 | 批样本数 | 学习率
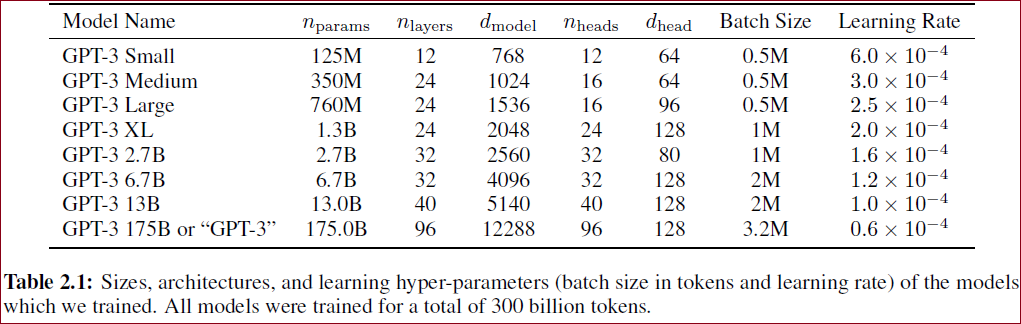
所有模型的上下文窗口大小都是2048个tokens。
数据集
训练数据
训练数据使用由万亿单词组成的Common Crawl数据集,庞大的语料使得每一个句子只用使用一次。
原始Common Crawl的不足:
非细致清洗的Common Crawl数据集质量逊于特别设计的数据集。
原始Common Crawl的改进:
根据与高质量引用语料的相似性来筛选Common Crawl的数据
对Common Crawl进行模糊去重处理,以防止验证集出现过拟合
额外加入高质量的语料(拓展版WebText,Books1,Books2和Wikipedia)以增强Common Crawl的丰富性
由于我们的训练集语料来源于网络数据,同时考虑到我们的模型具有很强的性能可能记录任何一条训练数据。所以,为了防止在测试集中出现pre-train阶段的原始数据,我们尝试移除训练集和测试集重复的部分(详见第四章)。然而,较高的训练费用导致即使我们发现在数据筛选阶段有一个bug,我们也没有资金重新训练了。
Common Crawl dataset包含近万亿单词,遍历一遍数据集就足够训练我们最大的模型。
然而,不进行数据清洗的数据集质量不高,采用以下三步清洗数据(采用了3步提升训练数据质量)
下载数据集的一个版本,根据与一系列高质量参考语料库的相似性过滤掉了部分语料;
1 采集过滤过的Common Crawl数据。
在文档级别、数据集内部和数据集之间执行了模糊重复数据消除,以防止冗余,并保持我们的作为过拟合的准确度量的验证集的完整性;
2 在文档粒度进行了去重操作。
将已知的高质量参考语料库添加到训练组合中,以增强Common Crawl并增加其多样性。
3 增加了更多的高质量数据语料。
使用的具体训练数据的比例如下表所示:
表2.2 实验使用的数据集
数据集 | 单词数量 | 训练集占比
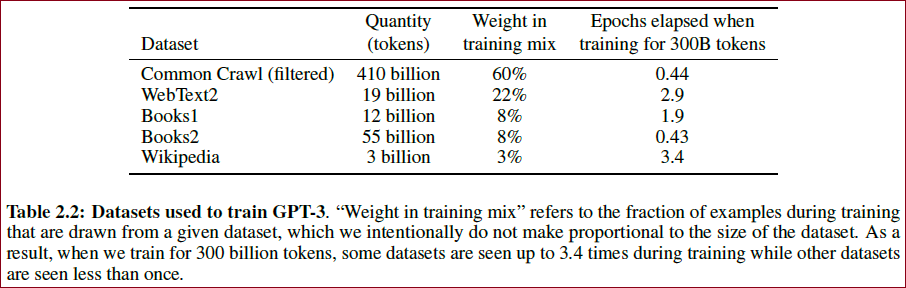
训练时数据不是按比例采样的,高质量的数据集会被采样更多次;
CommonCrawl和Books2采样少于一次,其他数据集被采样2-3次。
实验
在超过20个NLP数据集上测试GPT-3,包括问答、阅读理解、翻译等;
制定了测试GPT-3快速适应能力的新任务,如词汇重排、算术运算等;
测试了不同模型在零样本、一样本和少样本学习上的表现。
训练过程
批训练样本数:相关研究发现更大的模型能够使用更大的batch size。本文使用梯度噪音的大小来选择合适的batch size。
分布式训练:本文利用模型在矩阵乘法中和不同隐含层间的并行性以防止训练大模型时用尽内存。
有研究表明,更大的模型通常用更大的batch size,但是需要更小的学习率。
本文在训练中评估梯度噪音的大小来选择batch size。
利用矩阵乘法与网络不同层的并行性来进行分布式训练。
训练设备:使用微软提供的V100 GPU训练。
评估
单向任务评估:给定K个任务示例和待测样本的上下文信息,计算分别选取每个候选词的整个补全样本(K个任务示例+待测样本上下文+待测样本候选词)的似然,选择能产生最大样本似然的候选词作为预测。
二分类任务:将候选词从0和1变为False和True等更具有语义性的文本,然后使用上述单项选择任务的方式计算不同候选项补全的样本似然。
无候选词任务:使用和GPT-2完全一样参数设置的beam search方式,选择F1相似度,BLEU和精确匹配等指标作为评价标准。
结论
在多个任务上都取得了SOTA,如下:
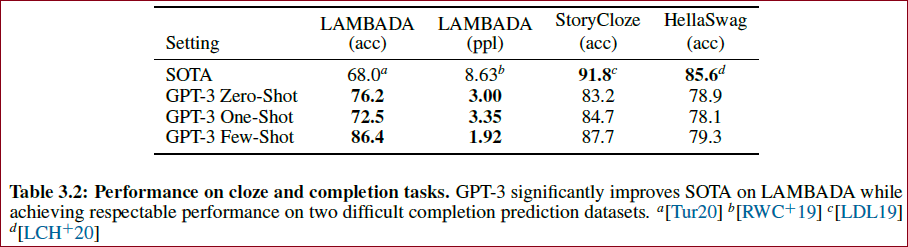
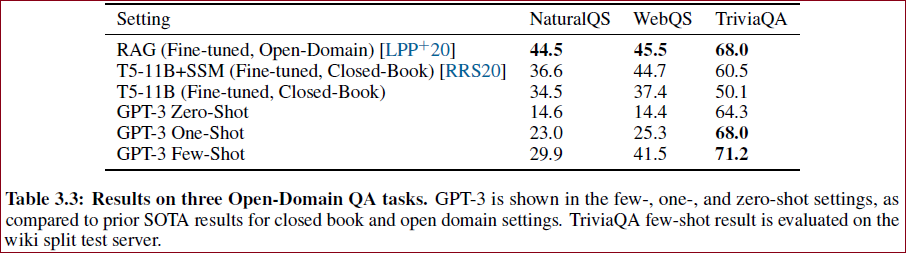
GPT-3在零样本和一样本设置下表现强劲,在少样本设置下的表现在某些任务上接近或超过微调SOTA。
模型规模越大,少样本学习的效果越好。
GPT-3展示出在推理时学习新任务的能力,但某些任务仍然表现欠佳。
这表明大规模预训练语言模型是发展通用语言系统的重要组成部分。
局限性:
长文本生成能力弱(比如写小说)
结构和算法上的局限性
往前看不能反着看;
每次均匀的预测下一个词,没有重点;
只是文本,没有视频或是物理交互;
样本有效性不够
是否从头开始学习了?
是否真正具有泛化性,而非大力出奇迹纯拼训练数据量
不可解释性
影响:
社会影响;
偏见;
思考
博文4
从Transformer一直到GPT-3,模型的结构并不复杂,但其使用的训练数据量越来越大,特别是GPT大模型,词数在亿级,纯纯是力大砖飞。而且GPT-3使用了微软DGX-1集群进行训练,有知乎回答指出其使用费用在百万人民币以上,这并非普通人所能承受。
因此自己做预训练基本上不太可能了,可能需要转而考虑利用现成的体量较小的预训练模型进行微调。
如果需要做微调,那么如何获取打了标签的网络设备配置文件。配置文件本身,由于配置文件备份或是版本管理软件,可以从ISP或是企业获取,但数据量可能不够用。对于打标签,这可能需要建立一套配置评估体系,实现对配置文件的自动评估,或是结合网络管理人员的领域知识进行评估。总之,这是一个要解决的问题。
我的总结:
训练数据一直在增大;
要能获取数据;
训练设备昂贵,个人使用可能还是要在体量小的模型上进行微调;
要学微调技术;
微调技术需要哪些要素?(see: pp012~pp020)
参考博文
【论文阅读】Language Models are Few-Shot Learners(GPT-3)
点评:★★★☆☆
这篇博文主要是对原文的概念进行了解读,但是有点散。无符号序列用的很突兀,没有感觉到行文的逻辑感和层次感。同时给了我一些其他方面的思考:我在写的时候,不能这样记录。要更有层次感才能方便我自己二次观看、复习。GPT-3阅读笔记:Language Models are Few-Shot Learners
点评:★★★★☆
这篇文章主要对全文的信息有一个整体的梳理,语言通俗易懂,案例也比较好。Language Models are Few-Shot Learners
点评:★★★☆☆
这篇文章很短,对整个paper的核心进行了一点点的要点梳理。总的来说有助于理解文章,所以三颗星!阅读笔记|Language Models are Few-Shot Learners
点评:★★★☆☆
这篇文章主要是对背景和整篇paper的主体进行了文字描述,辅助我理解了更多的背景知识,值得三颗星。GPT-3《Language Models are Few-Shot Learners》解读
点评:★★★★☆
虽然这篇文章很短,但是给出了非常干的干货,❶ 有对比描述;❷ 有新概念解释。我觉得很赞,给出四颗星。GPT-3(Language Models are Few-Shot Learners)论文阅读
点评:★★★☆☆
是对之前博文的一些重述,不过增加了一些新的补充,例如Prompt就是in-context learning,这是之前的几个博文没讲到的,果然,博文看多了是有帮助的!Re65:读论文 GPT-3 Language Models are Few-Shot Learners
点评:★★★☆☆
提供了一些背景知识,重要的是有一个git项目的链接和说明,让后期的复现有了基本参考。总体来说,描述的没有太大的逻辑,排版也略差,但是,万千若水,一瓢解渴就好了。
原文目录
1 Introduction 3 2 Approach 6 2.1 Model and Architectures 8 2.2 Training Dataset 8 2.3 Training Process 9 2.4 Evaluation 10 3 Results 10 3.1 Language Modeling, Cloze, and Completion Tasks 11 3.2 Closed Book Question Answering 13 3.3 Translation 14 3.4 Winograd-Style Tasks 16 3.5 Common Sense Reasoning 17 3.6 Reading Comprehension 18 3.7 SuperGLUE 18 3.8 NLI 20 3.9 Synthetic and Qualitative Tasks 21 4 Measuring and Preventing Memorization Of Benchmarks 29 5 Limitations 33 6 Broader Impacts 34 6.1 Misuse of Language Models 35 6.2 Fairness, Bias, and Representation 36 6.3 Energy Usage 39 7 Related Work 39 8 Conclusion 40 A Details of Common Crawl Filtering 43 B Details of Model Training 43 C Details of Test Set Contamination Studies 43 D Total Compute Used to Train Language Models 46 E Human Quality Assessment of Synthetic News Articles 46 F Additional Samples from GPT-3 48 G Details of Task Phrasing and Specifications 50 H Results on All Tasks for All Model Sizes 63
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。