LoRA1 - 论文精读学习笔记
LoRA: Low-Rank Adaptation of Large Language Models
标签:Parameter-Efficient Fine-Tuning论文链接:LoRA: Low-Rank Adaptation of Large Language Models
官方项目/代码:LoRA | Code2
发表时间:2021
You are what you eat.
And I'm cooking what I eat! :)
目录
LoRA - 论文精读学习笔记全文梗概背景问题陈述现状相关工作BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-modelsLST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning方法形式表达模型结构技术细节技术详述Low-Rank-Parametrized Update Matrices将LoRA应用于Transformer实验与分析对比实验训练参数量与性能对比实验对于GPT-3随着样本的增加的效果理解Low-Rank更新LoRA的应用示例总结参考博文
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
全文梗概
※ 研究主题:微调大模型
※ 问题背景:对比较大的模型进行全部参数的微调显得不太可行,例如GPT-3 175B,每个任务都部署一个单独的GPT-3,这个显得十分的昂贵。
※ 核心思想:是在预训练模型的基础上,通过注入可训练的低秩分解矩阵到Transformer架构的每一层,而不是对所有模型参数进行微调(fine-tuning),从而大幅减少下游任务的可训练参数数量。这种方法在保持预训练权重不变的情况下,通过优化低秩矩阵来间接训练密集层的权重更新。
※ 亮点:冻结了预先训练的模型权值,并将可训练的秩分解矩阵注入变压器架构的每一层,大大减少了下游任务的可训练参数的数量。该技术可以大大优化大模型Fine-tune所需的算力资源。
※ 结论:效果与全参微调相当或比全参要好,并且没有推理延迟。
梗概 本文介绍了一种名为LoRA的低秩适应方法,这是一种针对大型语言模型进行低秩适应的方法,通过在Transformer模型中引入可训练的低秩矩阵,减少预训练语言模型的下游任务参数,保持或提高性能,同时降低内存需求和推理延迟。实验显示LoRA在多种NLP任务上表现出色,且与现有技术兼容。
做法
把预训练LLMs里面的参数权重给冻结;
向transformer架构中的每一层,注入可训练的 rank decomposition matrices-(低)秩分解矩阵,从而可以显著地减少下游任务所需要的可训练参数的规模。
原理
LoRA的原理可以用一个简单的数学公式来描述。假设我们有一个预训练的权重矩阵
技术关键点
预训练权重固定:LoRA保持预训练模型的权重
注入低秩矩阵:在模型的每一层注入一个可训练的低秩矩阵
参数更新:在训练过程中,我们只更新矩阵
效果举例
相比于使用Adam的gpt3 175B,LoRA可以降低可训练参数规模,到原来的1/10000,以及GPU内存的需求是原来的1/3。
目的
主要是不想微调模型的所有参数,去满足下游任务,因为这个成本太大的,特别是大模型例如175B的GPT-3;
同时,这个方法也有人提出了相关的方法,可是这些方法存在问题,通过扩展模型的深度或减少模型的可用序列长度来实现存在推理延迟。最重要的是质量不太行呀。
灵感 学习到的过度参数化模型实际上存在于一个较低的intrinsic dimension(内在维度)上。即是训练下游任务不需要这么多参数,采用降秩的方法来保留最内在的参数。
Li C, Farkhoor H, Liu R, et al. Measuring the intrinsic dimension of objective landscapes[J]. arXiv preprint arXiv:1804.08838, 2018.
Aghajanyan A, Zettlemoyer L, Gupta S. Intrinsic dimensionality explains the effectiveness of language model fine-tuning[J]. arXiv preprint arXiv:2012.13255, 2020.
优点
训练更有效,训练参数少:显著减少了可训练参数的数量,例如,与GPT-3 175B微调相比,LoRA可以将可训练参数减少10,000倍。
降低了GPU内存需求,提高了训练效率:只共享一个大模型,对于不同的任务,只训练不同的A,B。
由于LoRA的简单线性设计,可以在部署时将训练矩阵与冻结权重合并,从而不会引入额外的推理延迟:在推理方面,线性合并,没有推理延迟;
LoRA与许多先前的方法正交,可以与其中许多方法结合,比如前缀微调(prefix-tuning)。LoRA与许多现有方法正交,可以与它们结合使用,例如前缀微调(prefix-tuning)。
※ 此外,文章还提供了对LoRA的实证研究,探讨了在语言模型适应中秩不足性的作用,并解释了LoRA的有效性。作者还发布了一个包,方便将LoRA与PyTorch模型集成,并提供了RoBERTa、DeBERTa和GPT-2的实现和模型检查点。
从这点来看,我觉得,这篇文章真的是好文章了!
主要贡献
1.LoRA方法的提出:文章提出了一种新的低秩适应(Low-Rank Adaptation, LoRA)方法,用于在不重新训练所有参数的情况下,对大型预训练语言模型进行有效适应。这种方法通过在Transformer架构的每一层注入可训练的低秩矩阵来实现,从而大幅减少了下游任务的可训练参数数量。
2.显著降低参数数量和内存需求:LoRA能够将可训练参数的数量减少10,000倍,同时将GPU内存需求降低3倍,这使得在资源受限的环境中部署和使用大型模型变得更加可行。
3.保持或提升模型性能:尽管LoRA减少了可训练参数的数量,但它在多个NLP任务上的性能与完全微调相当或更好,这表明LoRA是一种高效的模型适应方法。
4.无额外推理延迟:LoRA的设计允许在部署时将训练矩阵与冻结权重合并,这意味着在推理时不会引入额外的计算延迟,这与完全微调的模型相比是一个显著优势。
5.与现有技术的兼容性:LoRA可以与许多现有的模型适应技术结合使用,如前缀微调(prefix-tuning),这增加了LoRA的灵活性和实用性。
6.实证研究:文章提供了对LoRA方法的实证研究,探讨了在语言模型适应中秩不足性的作用,并解释了LoRA的有效性。
7.资源和工具的发布:作者发布了一个包,方便将LoRA与PyTorch模型集成,并提供了RoBERTa、DeBERTa和GPT-2的实现和模型检查点,这为研究社区提供了宝贵的资源。
总的来说,文章的主要贡献在于提出了一种新的、高效的大型语言模型适应方法,这种方法在减少资源消耗的同时,保持了模型的性能,并且易于与现有技术结合使用。
背景
自然语言处理中的应用通常需要使用大规模预训练的语言模型,并通过微调来适应不同的下游任务。微调更新了预训练模型的所有参数,但其缺点是导致新模型与原始模型一样庞大。一些方法尝试通过调整参数或学习外部模块来减少存储和加载任务特定的参数,以提高部署时的效率。然而,这些方法通常会引入推理延迟,并且无法与微调Baseline相匹配。
自然语言处理一个重要的范式是先训练一个通用的大语言模型然后再将其运用到特定任务或者领域。但是因为模型变得越来越大,我们很难在针对特定任务进行finetune。所以我们提出了LoRA。LoRA固化了所有原始的参数,并且在每一层Transformer里引入了可学习的参数,这就大大降低了下游任务的学习难度。对比完整finetune GPT-3,使用LoRA只需要使用1/10000的时间和1/3的GPU资源。除此之外,LoRA的准确度更高,inference时间也不增加。
将大模型在小任务上finetune是很常见的一种操作,但是非常不方便,因为这会消耗大量的资源。很多研究者试图通过只调整一部分可学习的参数来微调大模型,但是这都不能兼顾效率和准确率。基于“intrinsic rank”的假设,我们提出了LoRA,假设在模型适应过程中权重变化具有较低的内在秩。LoRA允许我们通过优化在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练权重不变。例如,在GPT-3 175B上,我即使在全秩很高时,非常低的秩也足够,这使得LoRA具有存储和计算效率。LoRA有以下几个优势:
一个预训练模型加上LoRA模块就能用于一个任务。如果有多个任务,预训练模型可以共享,只需要更改LoRA模块。所以节省存储空间。
只需要训练LoRA模块部分的参数,所以节省训练资源和时间。
没有额外的inference开销。
LoRA可以和其他任意方法结合。
问题陈述
我们研究的场景是给定了任务相关的prompt的条件下,提升算法的准确度。完整的finetuning要求我们对于每一个下游任务都训练一套新的完整参数,这不仅训练困难,存储也困难。于是我们提出LoRA,额外引入了一些参数,针对不同的任务都只需要更新这部分参数。
博文4 虽然LoRA与训练目标无关,但本文将重点放在语言建模上,作为代表用例。下面是对语言建模问题的简要描述,特别是在给定特定任务提示的情况下最大化条件概率。
假设一个预训练的自回归语言模型
,参数为 。例如, 可以是通用的多任务学习器,如GPT。模型应用于下游条件文本生成任务,如摘要、机器阅读理解和自然语言转换为SQL时,每个下游任务由context-target对应的训练数据集表示: ,其中, 和 都是token序列。在Full Fine-tuning过程中,将模型初始化为预训练的权值 ,并通过反复跟随梯度将模型更新为 ,使条件语言建模目标最大化: 这里的Full Fine-tune就是传统意义上的Fine-tuning,但是它的主要缺陷在于对于每一个任务,都需要学一个和原来参数量规模相同的
,因此,如果预训练模型很大(如GPT-3, ),存储和部署许多独立的微调模型实例可能是具有挑战性的。 本文提出一种更加parameter-efficient的方法,即用一个小得多的参数
来编码 ,那么这个任务就变成了优化参数 : 在随后的内容中,本文提出使用低秩表示(low-rank reprensentation)来编码
,这既节省计算又节省内存。当预训练模型为GPT-3 175B时,可训练参数的个数可小至原参数的0.01%。
现状
本文解决的问题并不新鲜。在迁移学习中,已经有很多尝试使模型更适应参数和计算效率。例如,语言建模领域有2种主要策略:添加适配器层(Adapters)和优化输入层激活。然而,这些策略都存在局限性,尤其在大规模和延迟敏感的生产场景中。适配器层引入了推理延迟并可能增加延迟,而前缀调整(Prefix-Tuning)面临性能非单调变化和减少序列长度对下游任务处理的挑战。
Adapter Layers引入了推理的latency(Adapters引入额外的推理延迟 (由于增加了模型层数))。现在的inference的处理器都能高效地并行,而它却是串行的。所以LoRA是并行的,推理速度就上来了。
直接优化Prompt非常难。举例 prefix tuning训练过程非单调,难以调参。
Prefix-Tuning难于训练,且预留给prompt的序列挤占了下游任务的输入序列空间,影响模型性能。
之前工作都提到Prefix-Tuning难于训练,模型性能也并非总是稳步提升。相比之下,LoRA的优势是容易训练,预留一些sequence做adaption会让处理下游任务的可用sequence长度变少,一定程度上会影响模型性能。
相关工作
Adapters 与 Prompting 都是轻量级的训练方法,所谓 lightweight-finetuning。
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
xxxxxxxxxx31for name, param in model.named_parameters():2 if '.bias' not in name:3 param.requires_grad=FalseBitFit也是为了解决大模型如何高效地给运用到下游任务。代码就三行,只finetune所有的bias,有着和LoRA一样的优势,其效果也接近full tuning。
LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning
LoRA是使用一个额外的模块产生feature,对LLM的feature进行微调。但是在training的过程中,也还需要逆推所有LLM模块的梯度。如果我们反过来,LLM的feature用来微调额外小模型的feature,那么不仅可以继承LoRA的所有优点,且在训练的时候也不需要计算LLM部分的梯度。
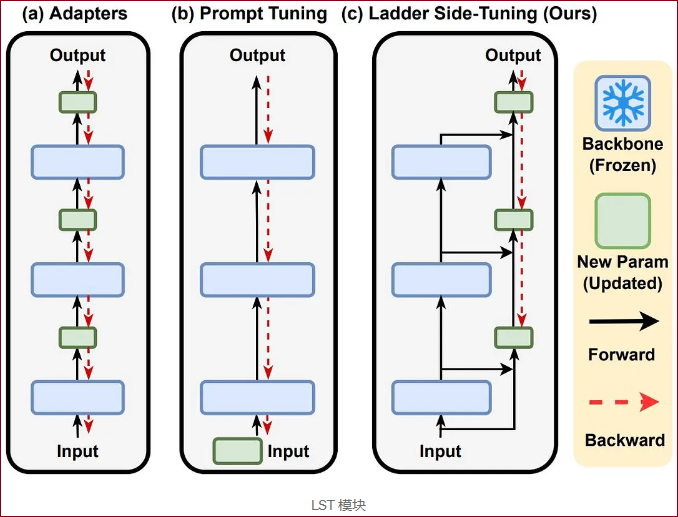
LST在原有大模型的基础上搭建了一个旁支,所有可训练的参数都只在额外分支上。LLM只为旁支提供feature,不需要计算梯度,因此可以达到训练加速的目的。
方法
形式表达
模型结构
点评:【言简意赅】
左边预训练模型权重不动;
只训练右边的A和B。
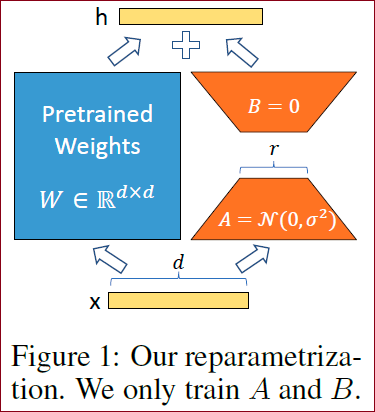
重新参数化:只有A, B是可以训练的。
博文6
虽然模型的参数众多,但其实模型主要依赖低秩维度的内容(
low intrinsic dimension),类比一下,似乎adaption好人使的本质也依赖于此,所以提出了Low-Rank Adaptation (LoRA)。LoRA的思想也很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的
intrinsic rank。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。具体来看,假设预训练的矩阵为
,它的更新可表示为: 其中,秩
。 对于
, 它的前向计算变为: 这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。并且,full finetuning可以被看做是LoRA的特例(当 r 等于 k 时)。
在生产环境部署时,LoRA可以不引入推理延迟,只需要将预训练模型参数
与LoRA参数进行合并(也就是所谓的模型合并)即可得到微调后的模型参数: ,在生产环境中像以前一样推理,即微调前计算 ,现在计算 ,没有额外延迟。现在不少模型仅发布LoRA权重,需要本地与基模型进行模型合并才能使用的原理就在于此。 LoRA与Transformer的结合也很简单,仅在QKV attention的计算中增加一个旁路,而不动MLP模块。

原文公式3和Figure 1 的对应关系
博文5
不过,如果是每个线性层W,都准备一个这样的B和A,那么对于原来的transformer里面的FFN的两个线性层,一个multi-head self-attention中的
, , , 的四个线性层,都可以按照这个方式改造。 所以,拿一个线性层举例,还是很具有代表性的。毕竟,说到底,transformer里面的基本模块,还是一个个的线性层。】
● 左边的蓝色的部分,冻住了。
● 右边的橙色部分,是可训练的。注意,r = rank,即矩阵的秩,可以是非常小的一个量。(例如,r=1, 2 在上面Figure 1 中)
● 上面还有个+号,是把左右两个分支,合并起来了。
● 下面的输入是x,一个d维度(例如,可以是d=12288)的向量;上面的输出是h,也是一个向量。
关键优势:
预训练的模型可以共享,并用于为不同的任务构建许多小型LoRA模块。可以通过替换图1中的矩阵A和B来冻结共享模型并有效地切换任务,从而显著降低存储需求和任务切换开销。
LoRA使训练更有效,并且在使用自适应优化器时将硬件进入门槛降低了3倍,因为不需要计算梯度或维护大多数参数的优化器状态。相反,只优化注入的小得多的低秩矩阵。
简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,与完全微调的模型相比,通过构建不会引入推理延迟。
LoRA与许多先前的方法正交,并且可以与其中许多方法组合,例如prefix-tuning。附录E中提供了一个例子。
文章主要聚焦于将LoRA在transformer注意力机制上进行使用,因为这也是transformer的精髓。
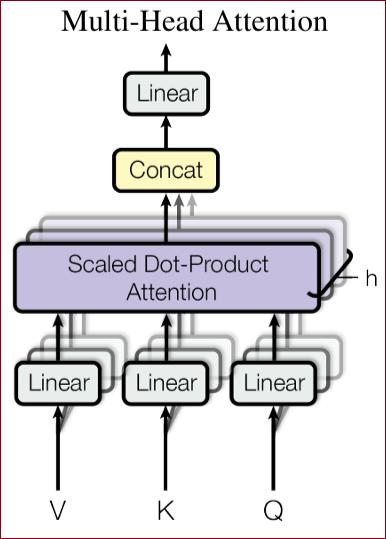
例如,我们在
Figure 1 解读:增加一个支路,支路由 A 和 B 两个矩阵组成。
用高斯分布初始化, 用全0初始化,保证一开始支路的输出结果不会影响主路,用公式就是下式。 至于在Transformer的具体实现,原文提到了“we only apply LoRA to Wq and Wv in most experiments for simplicity.”
其中
在训练的时候,
假设
而且,当我们面对不同的下游任务时,因为原本的预训练模型是冻结的,所以预训练模型用一个就行,只需要保存的参数就是加入的低秩矩阵,这样的话,也能节省大量的存储空间。
可以看个伪代码:
xxxxxxxxxx151class LowRankMatrix(nn.Module):2 def __init__(self, weight_matrix, rank, alpha=1.0):3 super(LowRankMatrix, self).__init__()4 self.weight_matrix = weight_matrix5 self.rank = rank6 self.alpha = alpha / rank # 将缩放因子与秩相关联7 # 初始化低秩矩阵A和B8 self.A = nn.Parameter(torch.randn(weight_matrix.size(0), rank), requires_grad=True)9 self.B = nn.Parameter(torch.randn(rank, weight_matrix.size(1)), requires_grad=True)10
11 def forward(self, x):12 # 计算低秩矩阵的乘积并添加到原始权重上13 # 应用缩放因子14 updated_weight = self.weight_matrix + self.alpha * torch.mm(self.B.t(), self.A)15 return updated_weight
※ Transformer中,自关注力有4个矩阵,MLP模块有2个矩阵;这里实验只关心自关注力相关的权重矩阵。
技术细节
假设预训练模型要进行常规全参数微调:
有条件
约束的,对 的自回归。 全参微调:每个下游任务都学习一个不同的参数集,代价太大,而且容易分裂。微调成本过高。
容易分裂是说,在一个数据集上微调,可能会拉低微调得到的模型在其他任务上的效果;无法达到真正的通用性。而且每个任务下的数据集都这么搞,代价(运算成本,使用成本)太高了。
其中
表示进行微调任务的数据集。
此时我们需要调整的参数就是全参数:
※ 如果是175B的模型,微调一个下游任务的模型,每次都要调整这么多参数,工作量巨大。
但是如果使用LoRA技术的话:
保持原来的参数不动,而引入少量的一些可训练参数,从而让这些参数帮忙做针对下游任务的“适应性微调”。
预训练模型的参数都冻结,不调整。
只是额外加一组小小的参数,也能做到和下游任务适配:
而此时需要调整的参数远远小于预训练模型的参数:
也就是说此时需要调整的参数很小。
博文4 ↓
技术详述
Low-Rank-Parametrized Update Matrices
神经网络中的Dense Layer通常包含许多矩阵乘法。先前的研究表明,在适应特定任务时,PLM可能具有较低的"内在维度",即使投射到较小的子空间,也可以有效地进行学习。受此启示,作者假设权重更新过程中也具有较低的"内在排名(intrinsic rank)"。作者使用低阶分解的方式表示预训练的权重矩阵
Figure 1 中展示了这种重新参数化的方式。对A使用随机高斯初始化,对B使用零初始化,因此
LoRA的推广形式允许训练预训练参数的子集,即在适应下游任务过程中权重矩阵的累积梯度更新不必具有全秩。这意味着Full Fine-tuning实际上是LORA的一种全秩的特殊情况。换句话说,当增加可训练参数的数量时,训练LoRA会大致收敛于训练原始模型,而Adapter的方法会收敛于MLP,Prefix-tuning的方法会收敛于不能处理长输入序列的模型。
LoRA在推理过程中没有额外的延迟。在部署到生产环境中时,我们可以显式地计算和存储
将LoRA应用于Transformer
在后续的论述中,作者们只对attention里面的四个线性层,进行LoRA的处理。对于mlp那边的两个线性层,还是冻结,不用LoRA。
整体动机,就是为原来的线性层变换,增加了一个low-rank的参数
,以及 和 的两个线性层。从而有: 。
在Transformer中使用LoRA可以将其应用于权矩阵的子集,从而减少可训练参数的数量。具体来说,在Self-attention模块中有四个权重矩阵(
对于实际的好处主要体现在内存和存储使用上。对于经过Adam训练的大型Transformer,当
此外,LoRA还允许在部署时低成本地在任务之间切换,只需交换LoRA权重,而不是所有参数,从而创建许多定制模型,可以在将预训练的权重存储在VRAM中的机器上动态交换。作者观察到,在GPT-3 175B的训练过程中,与完全微调相比,速度提高了25%,因为不需要计算绝大多数参数的梯度。然而,LoRA也有局限性,例如在单个前向传递中批量处理具有不同A和B的不同任务的输入时可能会面临推理延迟的问题。虽然对于不重要延迟的场景,可以不合并权重并动态选择LoRA模块来用于批量示例。
实验与分析
下面是一个初步的结果,对比几种baseline和RoLA的微调方法,指标用的是推理延时(milliseconds, ms, 用时,越小越好)。
推理用时的对比,越小越好。

显然,使用Adapter增加模型层数会增加推理的时长。
LoRA相较于Adapter不会显著增加推理的时间。
博文6 从Table 1 可以看出,对于线上batch size为1,输入比较短的情况,推理延迟的变化比例会更明显。不过个人认为,绝对延迟的区别不大。 :-)
选取RoBERTa、DeBERTa作为Baseline进行Full-tuning、Adapter和LORA的对比实验,结果如下:
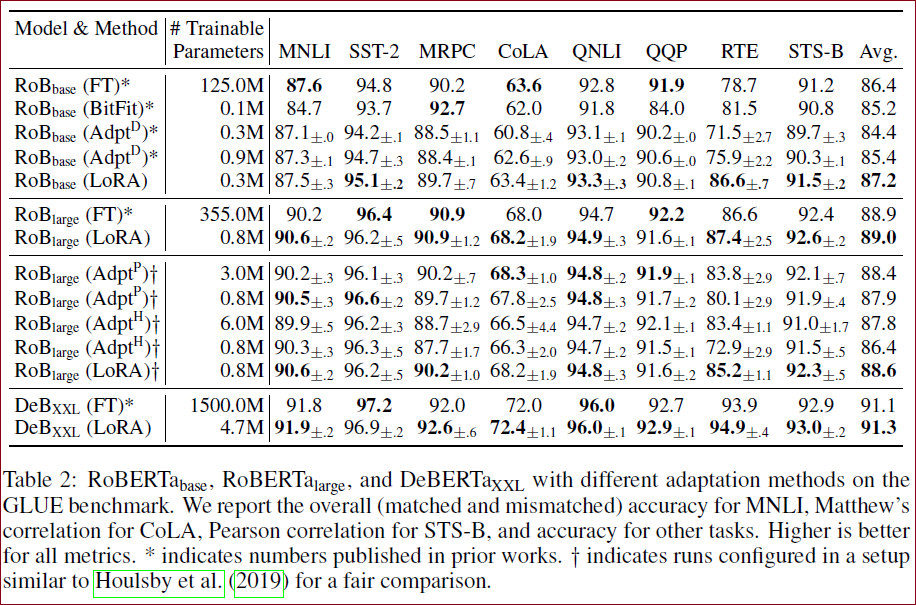
为了展示方法的普遍性,作者也使用GPT-2作为Baseline进行对比,具体如下。
对比实验
Fine-Tuning (FT):传统的微调。FT变体,只训练最后两层(FTTop2);
Bias-only or BitFit: 只训练bias vectors;
Prefifix-embedding tuning (PreEmbed):在输入标记中插入特殊的标记;
Prefix-layer tuning (PreLayer):是对前缀嵌入调优的扩展;
Adapter tuning:在自注意模块(和MLP模块)和后续的剩余连接之间插入适配器层;
Adapter_H:Houlsby et al. (2019) ;
Adapter_L:Lin et al. (2020);
Adapter_P:Pfeiffer et al. (2021);
Adapter_*D:AdapterDrop (R¨uckl′e et al., 2020);
所有模型,限制相关的参数大小规模
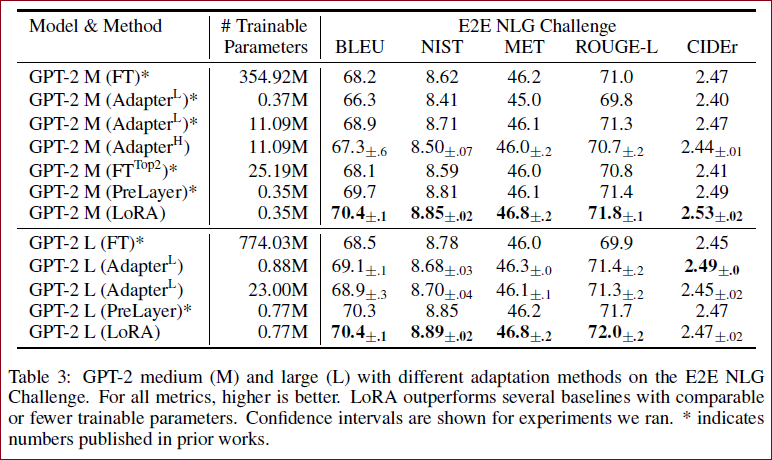
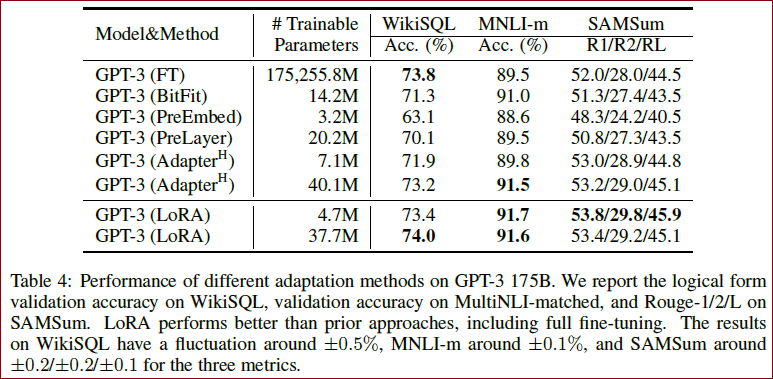
※ 作为LoRA的最终压力测试,我们将GPT-3扩展到1750亿个参数,如 Table 4 所示。注意,并不是所有的方法都单调地受益于更多可训练的参数,如 Figure 2 所示。可以观察到,当使用超过256个特殊token进行前缀嵌入调优或使用超过32个特殊token进行前缀层调优时,性能会显著下降。
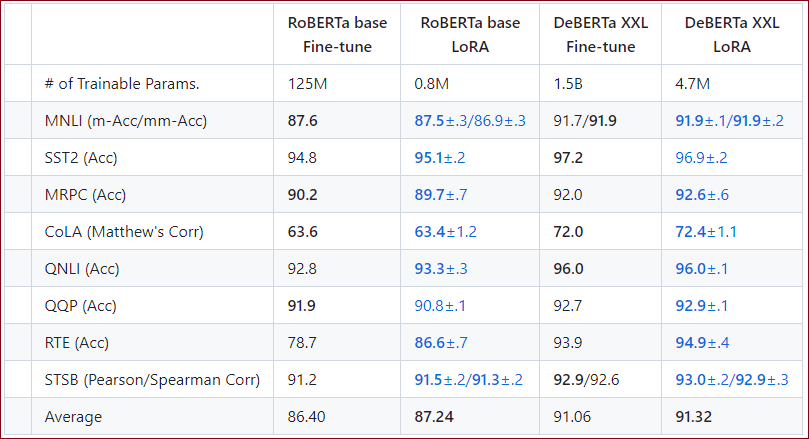
训练参数量与性能对比实验
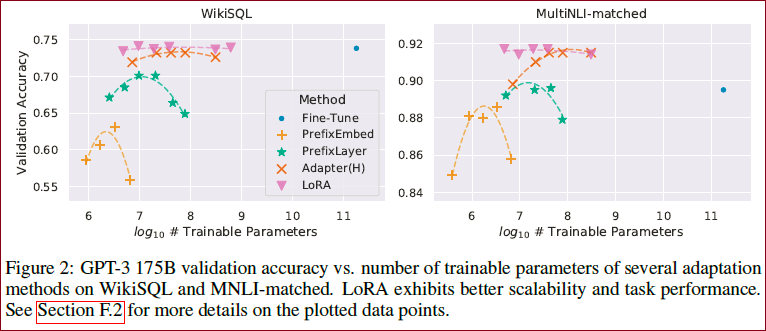
对于GPT-3随着样本的增加的效果
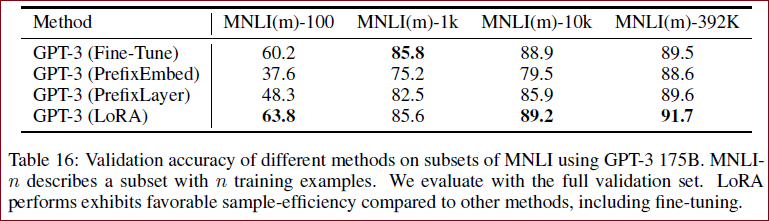
理解Low-Rank更新
鉴于LoRA的经验优势,作者进行了一系列的实证研究来回答以下问题:
给定一个参数预算约束,我们应该适应预训练的Transformer中权重矩阵的哪个子集以最大化下游性能?
“最优”适应矩阵
对于问题1,作者在GPT-3 175B上设置了18M的参数预算(如果存储在FP16中,则大约为35MB),如果只适应一种类型的注意力权重,则对应于
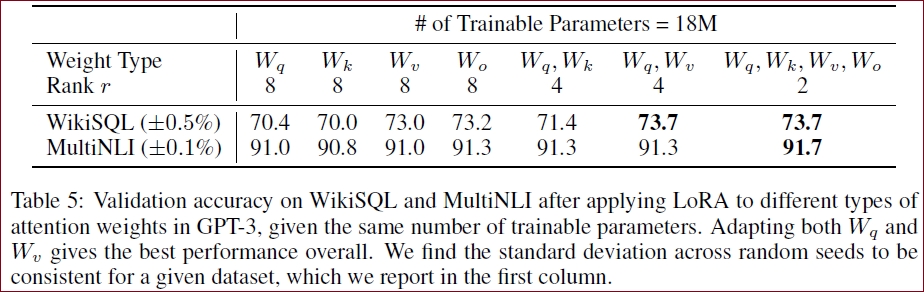
请注意,将所有参数都放在
或 中会导致性能显著降低,而同时调整 和 会产生最佳效果。这表明,即使是4个秩在 中捕获了足够的信息,使得适应更多的权重矩阵比适应具有较大秩的单一类型的权重更好。
对于问题2,Table 6 显示LoRA在非常小的
LoRA一起用到
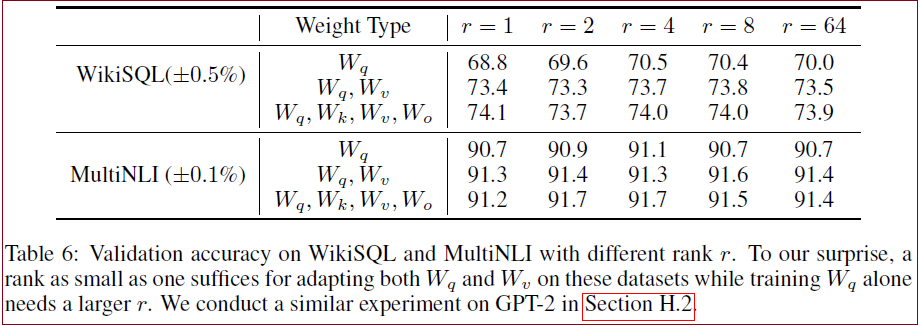
低秩已足够。
对于问题3,Table 7 可以得出几个结论。首先,与随机矩阵相比,

LoRA的应用示例
假设我们有一个预训练的GPT-3模型,并且希望将其应用于情感分析任务。使用LoRA,我们可以按照以下步骤进行:
固定GPT-3的预训练权重。
为模型的每一层注入低秩矩阵 A 和 B 。
训练注入的矩阵:使用情感分析任务的数据来训练 A 和 B ,而预训练权重保持不变。
模型部署:训练完成后,将 A 和 B 与原始权重合并,形成适应后的情感分析模型。
总结
文章通过实验表明,LoRA在多个NLP任务上的表现与完全微调相当,甚至在某些情况下更优。
从效果来看,不论预训练模型的大小,LoRA采用更少的参数,可以达到全参模型的更好的效果。
通过更少的参数去适应下游任务,主要是两个方向(adapter, soft Prompt):
adding adapter layers,optimizing some forms of the input layer activations
微调的主要缺点是,新模型包含的参数与原始模型一样多。
博文6
总结,基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的。它的应用自不必提,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
此外,考虑OpenAI对GPT模型的认知,GPT的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到四两拨千斤的效果。
就所需的硬件和为不同任务托管独立实例的存储/切换成本而言,对庞大的语言模型进行微调是非常昂贵的。本文提出LoRA,一种有效的自适应策略,既不引入推理延迟,也不减少输入序列长度,同时保持高模型质量。重要的是,通过共享绝大多数模型参数,它允许在作为服务部署时快速切换任务。虽然本文关注的是Transformer语言模型,但所提出的原则通常适用于任何具有密集层的神经网络。
未来的工作有很多方向。
LoRA可以与其他有效的自适应方法相结合,有可能提供正交改进。
微调或LoRA背后的机制尚不清楚——如何将预训练期间学习到的特征转化为下游任务?
本文主要依靠启发式方法来选择LoRA应用的权重矩阵。有没有更有原则的方法?
博文7
LoRA技术为大型语言模型的高效利用提供了一种新的可能性。通过低秩适应,我们可以在保持模型性能的同时,显著降低模型的计算和存储成本,使得大型模型的部署和应用变得更加容易。
参考博文
[论文阅读笔记77]LoRA:Low-Rank Adaptation of Large Language Models
点评:★★★☆☆,大概说了一下文章的情况,但是很多都是图、没啥解释,还需要再读一些博文,帮助理解。
论文阅读之LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS(2021)
点评:★★★☆☆,对原文的细节进行了解释,有些内容说的更浅显易懂,还是很棒的!!
论文阅读:LORA:Low-Rank Adaptation of Large Language Models 以及BitFit,LST
点评:★★★★☆,简短但有力,拓展了额外的知识,且博主有自己的思考,很赞呐!!
论文笔记:LoRA: Low-Rank Adaptation of Large Language Models
点评:★★★★★,看这篇博文的时候,让我有种折磨的感觉:很长,但是很有收获。我相信第二次看的时候会收获更大,所以还是坚持给读完,并做了内容摘录、分类。同时我还发现,一个领域中,经常写博文的就那几个~ 看来可以拓展一下人际,尝试联系一下?!
[速读经典]LoRA-给大语言模型做Low-Rank低秩改造
点评:★★★★☆,这篇文章将图和公式对应了起来,我感觉是一大亮点,让晦涩的内容和实际的图形结合起来了。一开始找的并不是这篇文章,而是通过2层追溯,最终找到了这个文章!很赞!感谢博主的认真撰写!
LoRA: Low-Rank Adaptation of Large Language Models 简读
点评:★★★☆☆,这篇文章给了一些细节的补充。还不错!!
点评:★★★☆☆,补充了一些细节。
LoRA - 论文精读学习笔记全文梗概背景问题陈述现状相关工作BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-modelsLST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning方法形式表达模型结构技术细节技术详述Low-Rank-Parametrized Update Matrices将LoRA应用于Transformer实验与分析对比实验训练参数量与性能对比实验对于GPT-3随着样本的增加的效果理解Low-Rank更新LoRA的应用示例总结参考博文
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。