CLIP1 - 论文精读学习笔记
Learning Transferable Visual Models From Natural Language Supervision
标签:Multimodal Large Language Models论文链接:Learning Transferable Visual Models From Natural Language Supervision
官方项目/代码:CLIP | Huggingface CLIP | Gitcode CLIP
发表时间:2021
You are what you eat.
And I'm cooking what I eat! :)
目录
CLIP - 论文精读学习笔记全文概述摘要背景方法CLIP是如何进行预训练的?CLIP是如何做zero-shot的推理的?Natural Language SupervisionCreating a Sufficiently Large Dataset - 数据集为什么CLIP要采用对比学习的方法训练整体架构Choosing and Scaling a Model训练主干模型推理过程代码与之前Zero-shot模型的对比实验Zero-Shot Transfer动机Using CLIP for zero-shot transferInitial comparison to visual N-GramsPrompt engineering and ensemblingAnalysis of zero-shot clip preformance大范围数据集结果模型的泛化性不足总结补充参考博文
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
全文概述
论文名:从自然语言监督中学习可转移的视觉模型
通过自然语言处理来的一些监督信号,可以去训练一个迁移效果很好的视觉模型。
想要解决的问题:之前的计算机视觉模型的数据集都是针对某一类特定任务,迁移效果较差,同时,一些训练时表现好的模型可能在测试中表现不佳。
主要贡献
如何利用自然语言作为监督信号
不预先定义标签类别,直接利用从互联网爬取的400 million 个image-text pair进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉——OCR、动作识别、细粒度分类。举例来说,无需利用ImageNet的数据进行训练,就可以达到ResNet-50在该数据集上有监督训练的效果。
利用language作为监督信号来学习视觉特征。
CLIP算法的核心 利用自然语言包含的监督信号来训练视觉模型。CLIP 是涉及文字和图片的多模态领域的工作,从文本中得到监督信号,引导视觉分类的任务。
论文方法的核心是在自然语言的监督中学习。
从自然语言中学习有几个潜在的好处:
和用于图像分类的标准标记相比,扩展自然语言监督要更容易,因为不要求标注内容需要采用机器学习的兼容模式;
自然语言可以在互联网上大量的文本中进行学习;
自然语言学习不仅是学习一种表现,同时也将其和语言表示联系起来,灵活的实现“zero-shot”转移。
CLIP主要完成的任务:
给定一幅图像,在32768个随机抽取的文本片段中,找到能匹配的那个文本。
CLIP为完成任务的做法:
为了完成这个任务,CLIP这个模型需要学习识别图像中各种视觉概念,并将视觉概念将图片关联,也因此,CLIP可以用于几乎任意视觉人类任务。例如,一个数据集的任务为区分猫和狗,则CLIP模型预测图像更匹配文字描述“一张狗的照片”还是“一张猫的照片”。
总结 是一个 zero-shot 的视觉分类模型,预训练的模型在没有微调的情况下在下游任务上取得了很好的迁移效果。是在跨模态训练无监督中的开创性工作。
zero-shot:是指零样本学习,在别的数据集上学习好了,直接迁移做分类。
👁🗨pp005 GPT2 - 论文精读学习笔记.md → 零样本学习
预训练部分
预训练网络的输入是文字与图片的配对,每一张图片都配有一小句解释性的文字。
将文字和图片分别通过一个编码器,得到向量表示。
这里的文本编码器就是 Transformer;而图片编码器既可以是 Resnet,也可以是 Vision transformer。
预训练采用对比学习,匹配的图片-文本对为正样本,不匹配的为负样本。收集到的文本-图像对,分别经过Text-Encoder和Image-Encoder,然后通过点积计算一个batch中文本和图像两两之间的相似度,得到一个batch size x batch size的相似度矩阵,对角线上的相似度值就是正样本的相似度值,因此在训练过程中优化目标就是让正样本的相似度值尽可能大。
摘要
现在的compute vision systems是训练模型来预测一组固定的、提前定义好的目标类别(比如ImageNet就是1000个类,COCO就是80个类),这种监督方式比较受限,因为需要额外的标记数据,限制了泛化性,如果有新的类别就要再去收集数据。直接从图像有关的原始文本中学习是一种很有前途的替代方案,它利用了更广泛的监督来源。给一些文本描述和一些图像,预测哪个标题和哪个图像搭配,这个预训练任务是一种有效且可扩展的方式,在从互联网收集的4亿(图像、文本)对的数据集上从头开始学习,能学到SOTA的image representations。预训练之后,natural language is used to reference learned visual concepts(or describe new ones) enabling zero-shot transfer of the model to 下游任务(自然语言引导模型去做物体的分类,分类不局限于已经学到的视觉概念,还能扩展到新的类别,从而现在学到的这个模型是能够直接在下游任务上做zero-shot的推理)。对超过30多个数据集进行测试来评估性能,涵盖OCR,视频中的动作识别、geo-localization和许多细粒度的分类,能轻松地转移到大多数任务,并且能达到和有监督的baseline方法差不多的性能,而无需任何数据集特定的训练。在ImageNet上,不使用那1.28 million训练样本,就能得到和有监督的ResNet-50差不多的结果。
背景
之前的一些弱监督方法效果不好的原因主要在scale,即数据集的规模和模型的规模。
论文的作者团队收集了一个超级大的图像文本配对的数据集,有400 million个图片文本的配对, 模型最大用了ViT-large,提出了CLIP(Contrastive Language-Image Pre-training),是一种从自然语言监督中学习的有效方法,在模型上一共尝试了8个模型,从resnet到ViT,最小模型和最大模型之间的计算量相差约100倍,迁移学习的效果基本和模型大小成正相关。尝试了30个数据集,都能和之前的有监督的模型效果差不多甚至更好。
OpenAI提出了DALL·E模型,该模型可以从包含大量概念的文本描述中生成相关图像。其名称DALL·E致敬了艺术家Salvador Dalí和皮克斯动画角色WALL·E。
DALL·E采用了基于Transformer的预训练结构,共有
对于文本token,使用标准的随机mask,通过GPT-3构造;
对于图像token,使用稀疏注意力(只计算某行、某列或局部),训练时图像尺寸被调整为
体模型采用极大似然算法进行自回归训练。
该模型能够从不同的文本描述中生成对应的图像:

上述结果是在生成的
方法
Contrastive Language-Image Pre-training (CLIP)方法用于在图像和文本数据集中进行匹配。具体地,训练一个文本编码器和图像编码器,分别得到文本和图像的编码,并计算两者的匹配程度。
给定
通过交叉熵损失使得匹配的
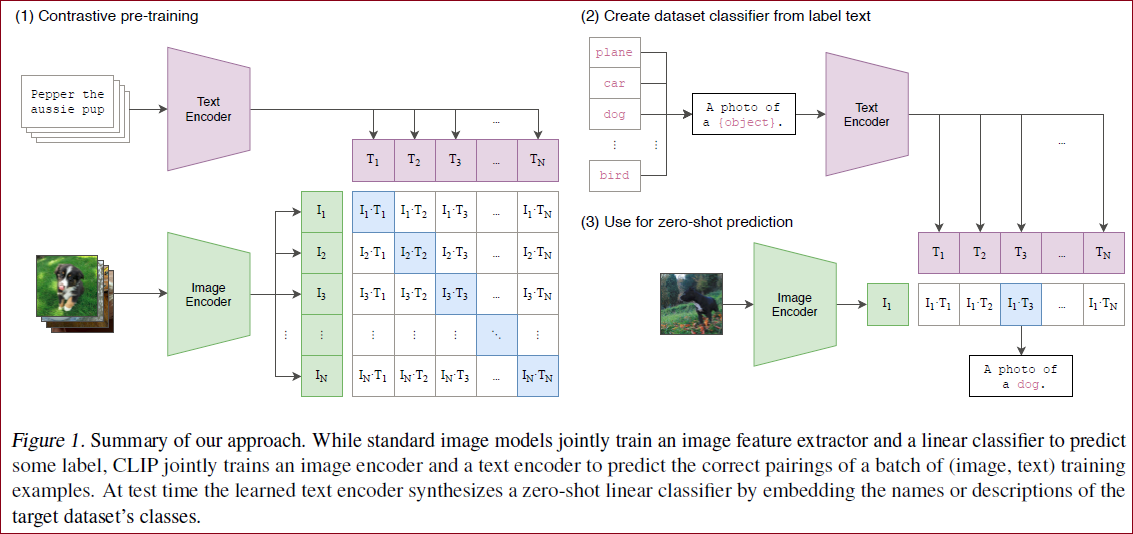
CLIP是如何进行预训练的?
模型的输入是图片和文字的配对,图片输入到图片的encoder得到一些特征,文本输入到文本的encoder得到一些特征,每个traning batch里有n个图片-文本对,就能得到
CLIP是如何做zero-shot的推理的?
预训练之后只能得到文本和图片的特征,是没有分类头的,作者提出一种利用自然语言的方法,prompt template。比如对于ImageNet的类别,首先把它变成"A photo of a {object}" 这样一个句子,ImageNet有1000个类,就生成1000个句子,然后这1000个句子通过之前预训练好的文本的encoder能得到1000个文本特征。直接用类别单词去抽取文本特征也可以,但是模型预训练的时候和图片配对的都是句子,推理的时候用单词效果会下降。把需要分类的图片送入图片的encoder得到特征,拿图片的特征和1000个文本特征算余弦相似性,选最相似的那个文本特征对应的句子,从而完成了分类任务。不局限于这1000个类别,任何类别都可以。彻底摆脱了categorical label的限制,训练和推理的时候都不需要提前定义好的标签列表了。
在进行图片分类任务的推理时,由于没有分类头,作者利用自然语言进行分类,也就是prompt template,模型1 首先需要将类别标签转换成和预训练时候一样的句子,因此这里用到了prompt操作,获得类别相应的句子。2 最后计算输入图片和每个类别对应句子的相似度,相似度最高的句子对应的类别的就是预测的类别。
Natural Language Supervision
方法的核心是the idea of learning perception from supervision contained in natural language.
相比其它的训练方法,从自然语言的监督信号来学习,有几个好处。
1 首先就是it's much easier to scale,不需要再去标注数据,比如用传统方法做分类,需要先确定类别,然后去下载图片再清洗,再标注,现在只需要去下载图片和文本的配对,数据集很容易就做大了,现在的监督对象是文本,而不是N选1的标签了。
2 其次,it doesn't "just" learn a representation but also connects that representation to language which enables flexible zero-shot transfer. 训练的时候把图片和文本绑在了一起,学到的特征不再单是视觉特征了,而是多模态的特征,和语言连在一起以后,就很容易做zero-shot的迁移学习了。多模态
Creating a Sufficiently Large Dataset - 数据集
a major motivation for natural language supervision是互联网上公开提供了这种形式的大量数据。现有的数据集不能充分反应这种可能性,因此仅考虑在这些数据集上的结果会低估这一研究方向的潜力。作者团队构建了400 million的图像文本对,这个数据集称作WIT(WebImage Text)。
Selection an Efficient Pre-Training Method
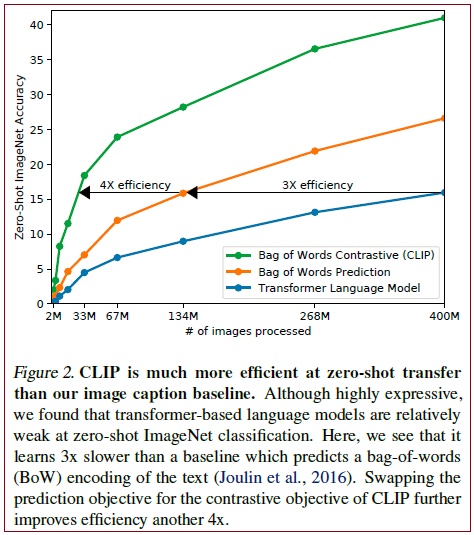
作者团队最初尝试的方法,类似VirTex,图像用CNN,文本用transformer,从头开始训练,预测图片的caption,这是一个预测型的任务,然而在efficiently scaling this method的时候遇到了困难。作者实验发现一个具有63 million参数的transformer language model,已经使用了ResNet-50 image encoder两倍的算力,learns to recognize ImageNet classes three times slower than a much simpler baseline that predicts a bag-of-words encoding of the same text.
这个任务在试图预测每张图片所附文本的确切单词(给定一张图片,去预测对应文本,要逐字逐句去预测文本的),这是个困难的任务,因为与图像同时出现的描述、评论和相关文本种类繁多。最近在图像对比学习方面的工作发现,contrastive objectives can learn better representations than their equivalent predictive objective. 其他一些研究发现,尽管图像的生成模型能够学习高质量的image representations,但它们的计算量比相同性能的对比模型要多一个数量级。基于这些发现,本文探索训练了一个系统来解决可能更容易的任务,即只预测哪个文本作为一个整体和哪个图像配对,而不是预测该文本的确切单词,效率提高了4倍。
科研好思路:转换问题,即,把困难的问题,转换为容易求解的问题。
给定N个图片文本对,CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of th
为什么CLIP要采用对比学习的方法
OpenAI是一家从来不愁计算资源的公司,他们喜欢将一切都GPT化(就是做生成式模型);
以往的工作表明(ResNeXt101-32x48d, Noisy Student EfficientNet-L2),训练资源往往需要很多,何况这些都只是在ImageNet上的结果,只是1000类的分类任务,而CLIP要做的是开发世界的视觉识别任务,所以训练的效率对于自监督的模型至关重要;而如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景);所以与其做默写古诗词,不如做选择题!(只要判断哪一个文本与图片配对即可);
通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍;
训练
CLIP在训练时使用了
结果 实验结果表明,对于文本编码器,采用bag-of-words (BoW)模型比Transformer的效率能提高3倍;采用对比损失比直接预测图像对应的文本效率能提高4倍。
CLIP训练完成后可以实现zero-shot的推理,即不经过微调的迁移学习,该过程是通过prompt templete实现的。以ImageNet数据集的分类任务为例,对于一千个类别标签,分别生成一千个对应的文本(如A photo of a #Class);通过CLIP匹配相似度最高的图像和文本,即可确定图像中出现目标的类别。
CLIP核心实现的伪代码:

博文2
有两个输入,一个是图片,一个是文本。图片的维度是[n,h,w,c],文本的维度是[n,l],l是指序列长度,然后送入到各自的encoder提取特征,image encoder可以是ResNet也可以是Vision Transformer,text encoder可以是CBOW,也可以是Text Transformer,得到对应的特征之后,再经过一个投射层(即W_i和W_t),投射层的意义是学习如何从单模态变成多模态,投射完之后再做l2 norm,就得到了最终的用来对比的特征 I_e 和 T_e ,现在有n个图像的特征,和n个文本的特征,接下来就是算consine similarity,算的相似度就是最后要分类的logits,最后logits和ground truth做交叉熵loss,正样本是对角线上的元素,logits的维度是[n,n],ground truth label是np.arange(n),(这里没有懂为什么np.arange(n)这样的ground truth),算两个loss,一个是image的,一个是text的,最后把两个loss加起来就平均。这个操作在对比学习中是很常见的,都是用的这种对称式的目标函数。
数据集很大很大,over-fitting不是主要问题,训练CLIP的细节也比较简单。从头开始训练,文本和图片的encoder都不需要使用预训练的weights,between the representation and the constastive embedding space也没有使用非线性的投射(projection),use only a linear projection to map from each encoder's representation to the multi-modal embedding space. 在之前对比学习的一些文章中提到过,非线性投射层比线性投射层能够带来将近10个点的性能提升,但是在CLIP中,作者发现线性还是非线性关系不大,他们怀疑非线性的投射层是用来适配纯图片的单模态学习的。也不需要做太多的数据增强,唯一用的是随机裁剪(a random square crop from resized images)。模型与数据集都实在是太大了,也不太好做调参的工作,在之前的对比学习中起到很重要作用的一个参数 temperature(controls the range of the logits in the softmax,
),作者把它设置成了可学习的标量,直接在模型训练过程中优化,不需要调参。
一个图片经过Image_encoder得到特征If,一个文本经过text_encoder得到特征Tf;
两个特征分别经过不同的FC层(目的是将单模态的特征转化为多模态,因为图片的特征可能本身就与文本的不一致,需要转换,但是这里没接激活函数,因为作者发现在多模态下接不接都一样);
再做一次L2归一化;
计算余弦相似度,得到logits;
logits与GT计算交叉熵目标函数;
而这里的GT就是一个单位阵(因为目标是配对样本之间相似性最强为1,而其他为0);
最后将图片的loss与文本的loss加起来求平均即可;
整体架构
Choosing and Scaling a Model
博文2 (这一部分感觉不重要,也没太看懂,主要就将image encoder选了ResNet和ViT两种结构,text encoder只用了transformer)
训练
图片这边共训练了8个模型,5个ResNet和3个transformer:
5个ResNet包括ResNet-50,ResNet-101;另外三个是根据efficientNet的方式对ResNet-50的宽度、深度、输入大小进行scale,分别对应原始ResNet50 4倍,16倍,64倍的计算量;
3个transformer包括ViT-B/32,ViT-B/16 和ViT-L/14。
所有的模型都训练了32个epoch,用的adam优化器,超参数是基于grid searches,random search和manual tuning来调整的,为了让调参更快,超参搜索的时候是用的Res50,只训练了一个epoch。batch size 32768,非常大,也用到了混合精度训练(更快更省内存)。还做了很多工程上的优化来加速的。最大的那个ResNet(RN50x64)在592个V100的GPU上训练了18天,最大的ViT在256个V100 GPU上只花了12天。对预训练好的ViT-L/14,又在这个数据集上fine-tune了一个epoch,用的是更大尺寸(336*336的),这个模型称作ViT-L/14@336px,论文后面提到的CLIP除非特别说明,均指ViT-L/14@336px。
主干模型
在文本方面就是Transformer;
在图像方面选择了5种ResNets(ResNet-50,ResNet-101,3个EfficientNet的变体,ResNet-50x4,ResNet-50x16,ResNet-50x64)和三种VIT(分贝是VIT-B/32,VIT-B/16,VIT-L/14)。
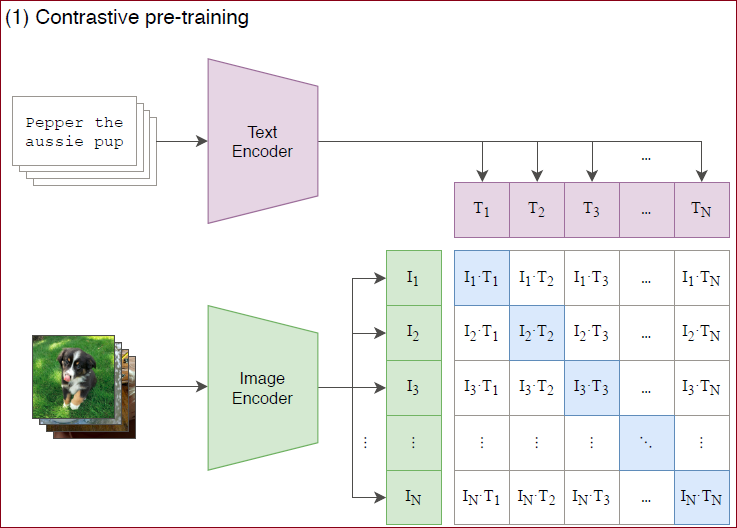
假设有
配对的句子和文本就是一对正样本(也就是对角线上的);不配对的就是负样本(对角线之外的)。
预训练网络的目标,就是最大化正样本对的余弦相似度,并最小化负样本的余弦相似度。
推理过程
CLIP 文章的核心 = Zero-shot Transfer!!
作者研究迁移学习的动机:
之前自监督or无监督的方法,主要研究 feature 学习的能力,model的目标是学习泛化性能好的特征,虽然学习到good-feature,但down-work中,还是需要有标签数据做微调。
作者想仅训练一个model,在down-work中不再微调。
给定一张图片,如何利用预训练好的网络去做分类呢?
给网络一堆分类标签,利用文本编码器得到向量表示。分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。
相比于单纯地给定分类标签,给定一个句子的分类效果更好。比如一种句子模板 A photo of a ...,后面填入分类标签。这种句子模板叫做 prompt(提示)。
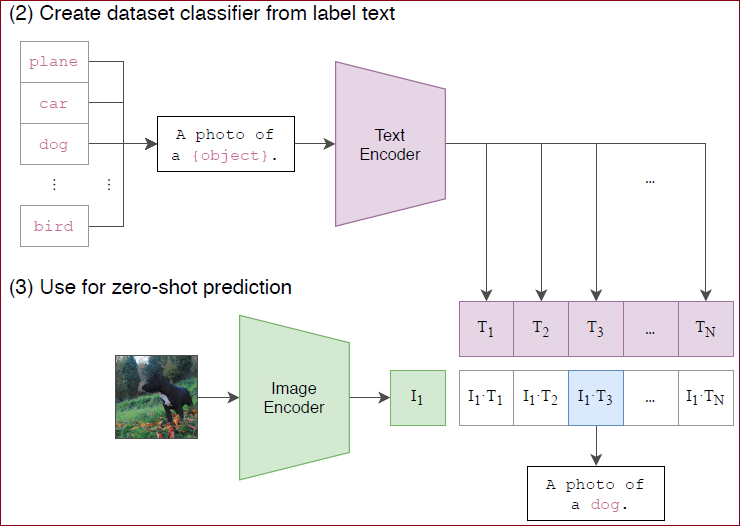
将要做的分类以填空的形式填进一句话中,以ImageNet为例就是1000句话输入Text Encoder得到输出;
将要识别的图片经过Image Encoder得到图片输出,比较文本的输出与图片的输出,选择最相似的那句话就是图片的类别;
代码
当使用训练好的CLIP模型进行推理时,首先需要使用clip.load()加载模型,然后分别对图像和文本进行前处理。
文字前处理是对数据集中的所有类别进行prompt engineering处理,将每个类别转换成句子,
clip.tokenize()将句子长度padding到77个token长度。下面的代码中,图像选取了CIFAR100数据集中的其中一张。
接下来,将图像和文字分别喂入图像编码器和文字编码器,提取图像特征和文字特征,分别将图像特征和文字特征正则化之后,计算图像特征和文字特征之间的相似度,并对相似度进行
softmax操作。
xxxxxxxxxx401# 下面代码使用CLIP进行zero shot预测,从CIFAR-100数据集中挑选一张图片,预测这张图像最有可能与此数据集中100个标签中哪一个标签最相似。2import os3import clip4import torch5from torchvision.datasets import CIFAR1006 7# Load the model8device = "cuda" if torch.cuda.is_available() else "cpu"9model, preprocess = clip.load('ViT-B/32', device) # 加载模型,返回的preprocess中包含一个torchvision transform依次执行Resize,CenterCrop和Normalization等操作。10 11# Download the dataset12cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)13 14# Prepare the inputs15image, class_id = cifar100[3637]16image_input = preprocess(image).unsqueeze(0).to(device) # 图像前处理17text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) # 文字前处理18 19# Calculate features20with torch.no_grad():21 image_features = model.encode_image(image_input) # 图像编码器提取输入图像的特征22 text_features = model.encode_text(text_inputs) # 文字编码器提取输入文字的特征23 24# Pick the top 5 most similar labels for the image25image_features /= image_features.norm(dim=-1, keepdim=True) # 正则化26text_features /= text_features.norm(dim=-1, keepdim=True) # 正则化27similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) #计算图像特征与文字特征之间的相似度28values, indices = similarity[0].topk(5)29 30# Print the result31print("\nTop predictions:\n")32for value, index in zip(values, indices):33 print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")34The output will look like the following (the exact numbers may be slightly different depending on the compute device):35Top predictions:36 snake: 65.31%37 turtle: 12.29%38 sweet_pepper: 3.83%39 lizard: 1.88%40 crocodile: 1.75%
与之前Zero-shot模型的对比
问题 Prompt 方法在什么时候用?
xxxxxxxxxx11Prompt是提示的意思,对model进行微调和直接做推理时有效;
问题 为什么要用 prompt engineering and ensembling?
xxxxxxxxxx31由于一个word 具有多义性,图片和文字匹配容易出错,所以作者将word放在语境中,来提高匹配度;2Prompt不仅能做匹配;3一旦加入这个prompt engineering and ensembling,准确度上升了1.3%;
最后在CLIP中,总共用了80个prompt template之多!
实验
Zero-Shot Transfer
动机
在计算机视觉中,zero-shot学习主要指 the study of generalizing to unseen object categories in image classification. 本文在更广的意义上使用这个术语,并研究对unseen datasets的泛化。
之前的那些自监督和无监督的方法,主要研究的是特征学习的能力,目标就是学一种泛化性比较好的特征,但即使学到了很好的特征,想应用到下游任务,还是需要有标签的数据做微调,所以有限制,比如下游任务数据不好收集,可能有distribution shift的问题。怎么做到只训练一个模型,后面不再需要微调了呢,这就是作者研究zero-shot迁移的研究动机。借助文本训练了一个又大又好的模型之后,就可以借助这个文本作为引导,很灵活的做zero-shot的迁移学习。
Using CLIP for zero-shot transfer
参考Figure 1
这个例子说的很好 在clip预训练好之后,就有2个编码器,一个是图像编码器,一个是文本编码器,推理时给定一张图片,通过编码器就能得到一个图片的特征,文本那边的输入就是感兴趣的标签有哪些,比如plane,car,dog等,这些词会通过prompt engineering得到对应的句子,比如 'A photo of a plane', 'A photo of a dog',有了这些句子以后,送入到文本编码器,就能得到对应的文本特征,这里假设是plane,car,dog这3个,然后拿这3个文本的特征去和那张图片的特征做余弦相似度,计算得到相似度以后再通过一个softmax得到概率分布,概率最大的那个句子就是在描述这张照片。
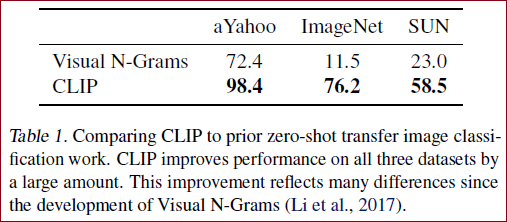
Initial comparison to visual N-Grams
visual N-Grams在ImageNet上只有11.5%的准确率,而CLIP已经达到了76.2%,和ResNet50精度差不多,完全没有用1.28 million的训练图片,直接zero-shot迁移就能得到76.2%。
当然作者也指出了这种对比不公平,CLIP的数据集是之前的10倍,而且视觉上的模型比之前要多100倍的计算,CLIP用的是transformer,2017年visual N-Grams发表的时候transformer还没出现。
Prompt engineering and ensembling
prompt是在做微调或者直接做推理时的一种方法,起到的是一个提示的作用,也就是文本的引导作用。
[为什么] 为什么要用Prompt engineering和Prompt ensembling呢?
一个原因是polysemy,多义性,即一个单词可能同时有很多含义,如果在做文本和图片匹配的时候,每次只用一个单词,也就是标签对应的那个单词,去做文本的特征抽取,就有可能遇到问题,因为缺乏上下文信息,模型无法区分是哪个词义,案例 比如在ImageNet里面同时包含两个类,construction cranes和cranes,在不同的语境下,这两个crane对应的意义是不一样的,在建筑工地环境下,construction cranes指的是起重机,作为动物,cranes指的是鹤,这就有歧义了。在Oxfort-IIIT Pet数据集中,有一类是boxer,根据上下文可知道它指的是一种狗,但对于缺乏上下文的文本编码器来说,极有可能把它当成拳击运动员。只用一个单词去做prompt,会经常出现歧义性的问题。
另一个问题是,在预训练的时候,匹配的文本一般都是一个句子,很少出现一个单词的情况,如果推理的时候,每次进来的是一个单词,可能就存在distribution gap的问题,抽出来的特征可能就不好。
做法 基于这两个问题,作者就提出了一种方式去做prompt template,利用这个模板“A photo of a {label}.” 把单词变成一个句子,把单词改成句子了,就不太会出现distribution gap的问题了,而且它的意思是“这是一张xxx的图片”,这个标签一般代表的都是名词,能一定程度上解决歧义性的问题。比如remote这个单词,就指的是遥控器,而不是遥远的。用上了提示模板之后,准确度提升了1.3%。
提示文本的好处 通过为每个任务自定义提示文本可以显著提高zero shot的能力。We found on several fine-grained image classification datasets that it helped to specify the category. 例如做Oxford-IIIT Pets这个数据集,它里面的类别肯定都是动物,给出的提示可以是这样的,“A photo of a {label}, a type of pet.” 这样就缩小了解空间,同样地在Food101数据集上可以指定“a type of food”,在FGVC Aircraft数据集上可以指定“a type of aircraft”,对于OCR数据集,作者发现在要识别的文本或数字旁加上引号可以提高性能。对卫星图像数据集,使用“a satellite photo of a {label}”这样的提示。
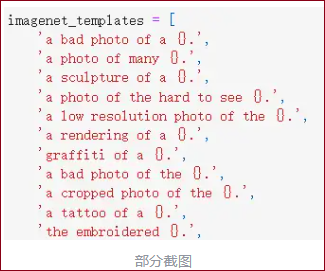
提示文本集成 作者还尝试集成多个zero shot classifiers,即prompt ensembling ,作为提高性能的另一种方式。这些分类器是在不同的上下文提示下得到的,比如“A photo of a big {label}" 和”A photo of a small {label}"。We construct the ensemble over the embedding space instead of probability space. This allows us to cache a single set of averaged text embeddings so that the compute cost of the ensemble is the same as using a single classifier when amortized over many predictions. 在ImageNet上,共集成了80个不同的context prompts,这比单个的default prompt 提高了3.5%的性能。
作者在 Prompt_Engineering_for_ImageNet.ipynb 列出了使用的这80个context prompts,比如有"a photo of many {}"适合包含多个物体的情况,"a photo of the hard to see {}"可能适合一些小目标或比较难辨认的目标。
Analysis of zero-shot clip preformance
性能分析部分。博文2没有给出!
大范围数据集结果
在imagenet上即使是zero-shot也可以达到ResNet-50的效果,迁移能力令人震惊,但是在一些难以用文本描述的数据集上,如纹理数据集,表现效果较差,且在各数据集上的效果与SOTA比还是有差距,不过其他的都是监督学习,所以总体来看效果还是十分不错。
做了27个数据集的分类任务,baseline是ResNet-50,ResNet-50是有监督模型在各个数据集上训练好的, 然后两个模型在其他数据集上zero-shot;
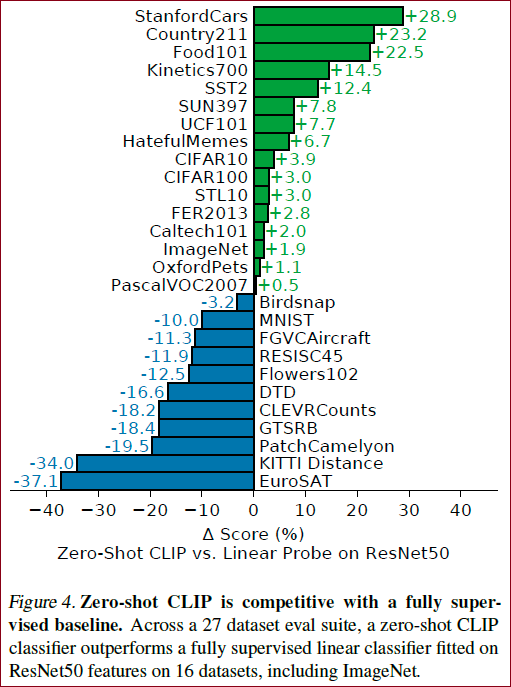
在大多数分类任务,给车、食物等做分类的问题上CLIP都表现的很好, 但是在DTD这种纹理进行分类或CLEVRCounts给物体计数的任务,对于CLIP无监督模型来说就很难了;
※ 所以作者认为在这些更难的数据集做few-shot可能比zero-shot更好;
推理过程中最关键的一点,在于我们有很高的自由度去设置“多项选择题”。从前的分类网络的类别数量是固定的,一般最后一层是跟着 softmax 的全连接层;如果要更改类别数量,就要更换最后一层;并且预测的内容是固定的,不能超过训练集的类别范围。
但对于 CLIP 来说,提供给网络的分类标签不仅数量不固定,内容也是自由的。如果提供两个标签,那就是一个二分类问题;如果提供1000个标签,那就是1000分类问题。标签内容可以是常规的分类标签,也可以是一些冷门的分类标签。博文1我认为这是 CLIP 的一大主要贡献——摆脱了事先定好的分类标签。
模型的泛化性
当数据有distribution shift的时候,模型的表现如何,这是CLIP最惊艳的结果:
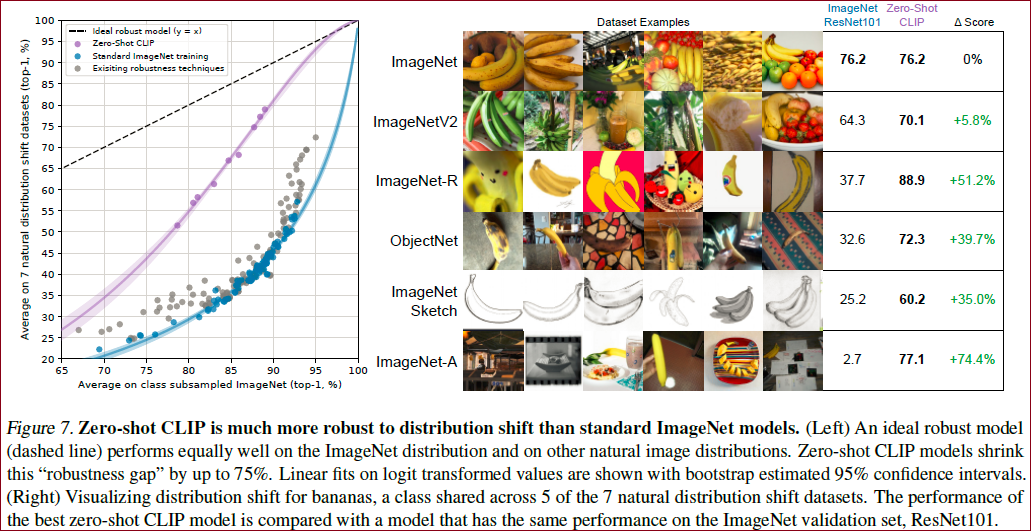
可以看出CLIP在数据分布的偏移样本上,远远超过ResNet101,而且结果保持地依旧稳健;
以及作者构造了WebImageText (WIT) 数据集。包含4亿个图片-文本对。
不足
Zero-shot的CLIP比基于ResNet-50特征的线性分类器相比具有优势,但在很多任务上,仍逊色于SOTA模型。
CLIP在细分类数据集上表示不好;CLIP不擅长处理抽象任务,比如数一数图像中物体的个数;CLIP对一些不包含预训练集中的新型任务,表现也不好, 比如对一张图像中到最近汽车的距离进行分类。
对于一些真正的分布外的数据,CLIP的泛化性能很差。
CLIP本质上还是在有限的类别中进行推理,相比于image caption直接能生成新的输出,还是具有局限性的。一个值得尝试的简单想法是将对比和生成目标进行联合训练,整合CLIP的有效性和caption模型的灵活性。
CLIP仍然没有解决深度学习中的
poor data efficiency问题。CLIP与自监督和自训练结合训练会是一个提高数据效率方面的方向。CLIP 虽然一直强调zero-shot,但是在训练过程中,也反复以数据集的validation performance指导CLIP的表现,并不算真实的zero shot。如果能够创造一个验证zero-shot的迁移能力的新数据集,将会解决这种问题。
4亿图像文本对,不论图像和文本都是从网上爬下来的。而是这些图像文本对没有进行过滤和处理,难免会携带一些社会性偏见。
很多复杂的任务和视觉概念很难仅仅通过文本指定。未来的工作需要进一步开发一种将CLIP强大的zero shot性能与few shot学习相结合的方法。
作者想要:
xxxxxxxxxx11把一切都GPT(生成式模型)化,因为CLIP还是根据给定的1000个选项去选择到底是那个类别,作者更想直接一张图片,然后生成对应的标题。但受限于计算资源,作者没法做成“自动生成模型”的网络。(以后的DALL)
总结
CLIP 的最大贡献在于打破了固定种类标签的桎梏,让下游任务的推理变得更灵活。
在 zero-shot 的情况下效果很不错。可以拓展到其他领域应用,包括物体检测、物体分割、图像生成、视频动作检索等。
补充
其它好玩的应用:
StyleCLIP:根据输入的文本进行人脸编辑
CLIPDraw:根据输入的文本生成画
CLIPS:根据输入的文本从视频中检索到相关物体
参考博文
【论文阅读】Learning Transferable Visual Models From Natural Language Supervision
点评:★★★★☆,博文有自己的总结和思考,帮助我第一遍理清了一些CLIP的相关知识。还不错!
CLIP论文 | Learning Transferable Visual Models From Natural Language Supervision
点评:这篇博文简直很棒!用例说的非常详细,就应该写出这样的博文才是赞的! ★★★★★
Learning Transferable Visual Models From Natural Language Supervision
点评:补充了一些背景知识,★★★☆☆。
CLIP:Learning Transferable Visual Models From Natural Language Supervision
点评:作者对一些概念和文字进一步叙述了一下,能够帮助读者进一步理解,还不错,★★★☆☆。
CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》
※ 这篇文章主要说的内容还是不错的!但是我没有详细看,等后面需要用到或者想要进一步研究的时候,可以深入看看这篇博文。暂定★★★★★。2024年9月24日 11:39:10
CLIP - 论文精读学习笔记全文概述摘要背景方法CLIP是如何进行预训练的?CLIP是如何做zero-shot的推理的?Natural Language SupervisionCreating a Sufficiently Large Dataset - 数据集为什么CLIP要采用对比学习的方法训练整体架构Choosing and Scaling a Model训练主干模型推理过程代码与之前Zero-shot模型的对比实验Zero-Shot Transfer动机Using CLIP for zero-shot transferInitial comparison to visual N-GramsPrompt engineering and ensemblingAnalysis of zero-shot clip preformance大范围数据集结果模型的泛化性不足总结补充参考博文
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。