S-LoRA1 - 论文精读学习笔记
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
标签:Parameter-Efficient Fine-Tuning论文链接:S-LoRA: Serving Thousands of Concurrent LoRA Adapters
官方项目/代码:S-LoRA
发表时间:2023
You are what you eat.
And I'm cooking what I eat! :)
目录
S-LoRA - 论文精读学习笔记背景摘要回顾 - LoRA全文梗概S-LoRA解决了什么问题?S-LoRA为什么能做到的?创新点重点内容1 批处理※ token-level的批处理调度方法※ 对请求按照Adapter聚在一起※ 准入控制※ 新的GPU算子2 内存管理Unified Paging3 张量并行评估补充参考博文
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
背景
一般来说,大语言模型的部署都会采用「先预训练 — 然后微调」的模式。但是,当针对众多任务(如个性化助手)对 base 模型进行微调时,训练和服务成本会变得非常高昂。
低秩适配(LowRank Adaptation,LoRA)是一种参数效率高的微调方法,通常用于将 base model适配到多种任务中,从而产生了大量从单一 base model衍生出来的 LoRA adapters。
这种模式为服务过程中的批量推理(batch inference)提供了大量机会。LoRA 的研究表明了一点,只对适配器权重进行微调,就能获得与全权重微调相当的性能。问题 虽然这种方法可以实现单个适配器的低延迟推理和跨适配器的串行执行,但在同时为多个适配器提供服务时,会显著降低整体服务吞吐量并增加总延迟。总之,如何大规模服务于这些微调变体的问题仍未得到解决。
博文3 对于行业大模型来说,仅仅拥有强大的基座大模型是远远不够的。而通过对一个基座模型使用行业数据进行LoRA微调,可以得到多个小型LoRA适配器作为微调结果。这些适配器的参数虽然非常小(例如只有基础模型参数的1%),但却能更好的适用于特定行业。然而在部署上,又会面临一个新的问题:一个base model+几千个lora,怎么serving?
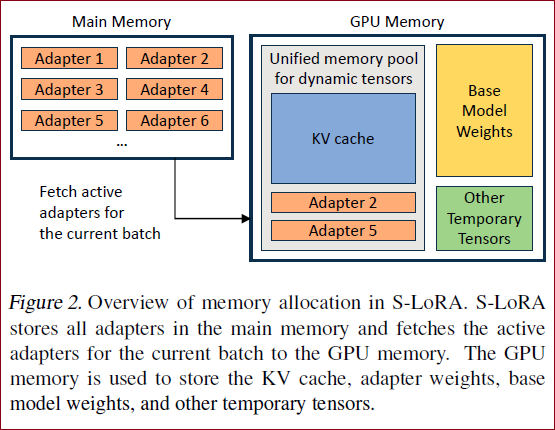
核心 S-LoRA解决的就是如何在单台机器上部署数千个同源的LoRA adapter。当然前提是这些LoRA adapter都是来自同一个base model的权重。针对从同一基础模型用LoRA微调出来的多个adapter结果,S-Lora的提出者提出了一套高效部署方案。通过扩展Batching策略,PageAttention内存管理策略和并行策略,实现单个GPU服务上千个LoRA adapter的效果。
博文4 当base大模型在垂类任务上表现一般,需要少量参数微调时,流行的做法就是对其进行少量参数(LoRA)微调时。这样难免存在每个任务有个单独的adapter ,推理时需要把adapter与base model参数加到一起再推理。这样做的结果是,在推理时依然是一任务一模型,仿佛又回到了BERT时代,但是每个模型的参数却大得多,推理需要的显存更多。既然base模型一样,有没有什么方法能够节省推理的GPU显存,构造一个统一的推理模型,能够满足所有的业务场景呢?S-LoRA为我们提供了一种很好的工程上的解决方案。
摘要
我们观察到,这种范式在服务期间的batch inference中呈现出重大机遇。为了利用这些机会,我们提出了S-LoRA,一个为可扩展服务许多LoRA adapters而设计的系统。S-LoRA将所有adapters存储在main memory中,并将当前运行查询所使用的adapter提取到GPU memory中。
为了有效使用GPU memory并减少碎片化,S-LoRA提出了Unified Paging。
Unified Paging使用统一的memory pool来管理具有不同rank的动态adapters权重和具有不同序列长度的KV cache tensors。
此外,S-LoRA采用了一种新颖的张量并行策略和高度优化的自定义CUDA内核,用于LoRA计算的异构批处理。
总的来说,这些特性使S-LoRA能够在单个GPU或跨多个GPU上以很小的开销服务数千个LoRA adapters。与诸如HuggingFace PEFT和vLLM(具有对LoRA服务的简单支持)等最先进的库相比,S-LoRA可以将吞吐量提高多达4倍,并将服务的适配器数量增加几个数量级。因此,S-LoRA能够可扩展地服务许多特定任务的微调模型,并为大规模定制微调服务提供潜力。
回顾 - LoRA
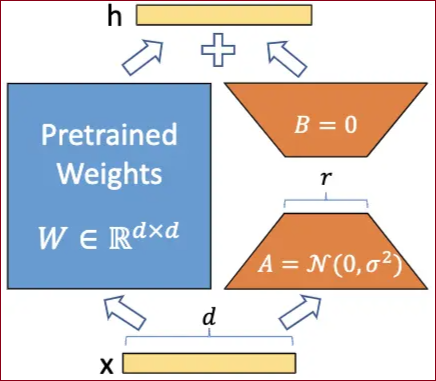
LoRA:Low-Rank Adaptation,LoRA冻结预训练模型权重并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量(推理参数不变)。它基于的假设就是,下游任务需要修改的特征空间是低秩的,即只要针对优化少量参数即可。类似是传统的Adapter思想,但是它的设计比较巧妙,就是用d×r和r×d(r远小于d,r一般又被称为秩)的参数矩阵A×B来做自适应学习的那部分(如下图所示),推理时只要跟base模型的d×d参数矩阵加起来就可以了,不会有额外的推理需求增加。但是这样做有个隐患就是,依然是一任务一模型。之前的解决方案是通过对参数矩阵的加减实现一个base模型加载多个adapter,但是这样依然不能实现在一个batch里同时使用多个lora。
全文梗概
来自 UC 伯克利、斯坦福等高校的研究者提出了一种名为 S-LoRA 的新微调方式。
S-LoRA 是专为众多 LoRA 适配程序的可扩展服务而设计的系统,它将所有适配程序存储在主内存中,并将当前运行查询所使用的适配程序取到 GPU 内存中。
S-LoRA 提出了「统一分页」(Unified Paging)技术,即使用统一的内存池来管理不同等级的动态适配器权重和不同序列长度的 KV 缓存张量。
此外,S-LoRA 还采用了新的张量并行策略和高度优化的定制 CUDA 内核,以实现 LoRA 计算的异构批处理。
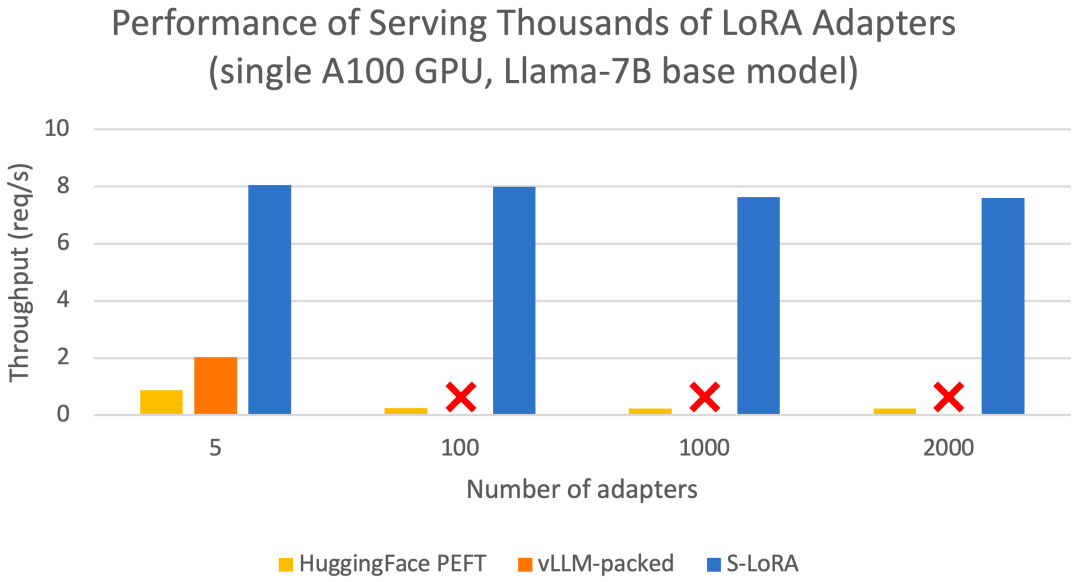
这些功能使 S-LoRA 能够以较小的开销在单个 GPU 或多个 GPU 上为数千个 LoRA 适配器提供服务(同时为 2000 个适配器提供服务),并将增加的 LoRA 计算开销降至最低。相比之下,vLLM-packed 需要维护多个权重副本,并且由于 GPU 内存限制,只能为少于 5 个适配器提供服务。
对比 与 HuggingFace PEFT 和 vLLM(仅支持 LoRA 服务)等最先进的库相比,S-LoRA 的吞吐量最多可提高 4 倍,服务的适配器数量可增加几个数量级。因此,S-LoRA 能够为许多特定任务的微调模型提供可扩展的服务,并为大规模定制微调服务提供了潜力。

S-LoRA解决了什么问题?
S-LoRA实现了同时用多个LoRA的Adapters并行推理,即1 base model + n Adapters(A×B的部分),相比于n models,在推理时就可以减少显存占用。
S-LoRA为什么能做到的?
S-LoRA在具体实现上有很多细致的设计,能够真正支持多Adapters并行化推理,又能尽量减少推理显存消耗,并减少相比一任务一模型的结构的中间的性能损失。论文主要从3大方面来解释它的做法的,分别是:推理请求的并行化处理、内存管理和张量并行。
创新点
S-LoRA 包含三个主要创新部分。
论文的第 4 节介绍了批处理策略,该策略分解了 base 模型和 LoRA 适配器之间的计算。此外,研究者还解决了需求调度的难题,包括适配器集群和准入控制等方面。跨并发适配器的批处理能力给内存管理带来了新的挑战。
第 5 节,研究者将 PagedAttention 推广到 Unfied Paging,支持动态加载 LoRA 适配器。这种方法使用统一的内存池以分页方式存储 KV 缓存和适配器权重,可以减少碎片并平衡 KV 缓存和适配器权重的动态变化大小。
最后,第 6 节介绍了新的张量并行策略,能够高效地解耦 base 模型和 LoRA 适配器。
Contributions
Unified Paging:为了减少显存碎片和增加batch size,S-LoRA 引入了一个统一内存池。这个内存池通过一个统一页机制管理动态adapters的权重和KV cache tensors。
Heterogenous Batching: 为了最小化latency的overhead,当batching不同rank的adapters时,S-LoRA 实现了高度优化的定制化CUDA kernels。这些kernels直接在非连续内存上运行,并与内存池设计保持一致,有助于 LoRA 的高效批量推理。
S-LoRA TP:为了确保跨多个 GPU 的有效并行化,S-LoRA 引入了一种新颖的张量并行策略。 与基本模型相比,这种方法所增加的 LoRA 计算的通信成本最低。 这是通过在小的中间张量上调度通信并将大的中间张量与基本模型的通信融合来实现的。
重点内容
1 批处理
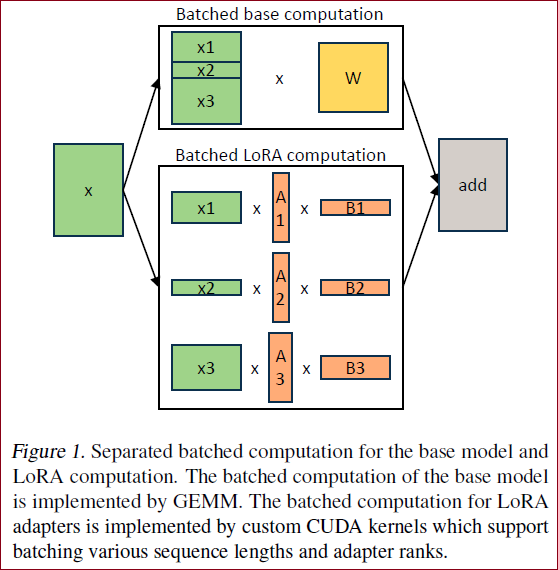
为了减少base model的数量,本文将base模型和adapter分开计算(如 Figure 1 所示),而不是直接把参数合在一起了,是在分别计算后再把两个模型输出的结果加起来。
道理看起来简单,实际操作却暗含很多需要优化的问题:lora的每个adapter的秩不一定一样,就导致每个批次里请求的adapter参数矩阵大小不一,如何并行化处理?每批次请求用到的adapter都不一样,如何调度?等等问题
对于单个适配器,Hu et al., 2021 推荐的方法是将适配器权重合并到 base 模型权重中,从而得到一个新模型(见公式 1)。这样做的好处是在推理过程中没有额外的适配器开销,因为新模型的参数数与 base 模型相同。事实上,这也是最初 LoRA 工作的一个突出特点。
本文指出,将 LoRA 适配器合并到 base 模型中对于多 LoRA 高吞吐量服务设置来说效率很低。取而代之的是,研究者建议实时计算 LoRA 计算
在 S-LoRA 中,计算 base 模型被批处理,然后使用定制的 CUDA 内核分别执行所有适配器的附加
如果将 LoRA 适配器存储在主内存中,它们的数量可能会很大,但当前运行批所需的 LoRA 适配器数量是可控的,因为批大小受 GPU 内存的限制。为了利用这一优势,研究者将所有的 LoRA 适配卡都存储在主内存中,并在为当前正在运行的批进行推理时,仅将该批所需的 LoRA 适配卡取到 GPU RAM 中。在这种情况下,可服务的适配器最大数量受限于主内存大小。Figure 2 展示了这一过程。第 5 节也讨论了高效管理内存的技术。
※ token-level的批处理调度方法
为了实现显存的尽可能高的利用率,这里的batch request调度采用了orca(Yu@OSDI2022, ORCA: A Distributed Serving System for Transformer-Based Generative Models)调度方法,实现token-level的迭代调度。详细讲解可以看作者自己的报告视频(一般的批处理调度-视频第6分钟左右; orca批处理调度-第8分钟左右):Orca: A Distributed Serving System for Transformer-Based Generative Models | USENIX 简要来说,就是orca构造了一个请求池,每并行处理完所有序列的一个token长度就把没结束生成的requests放回池子里,新来的requests也按照来的顺序放在一起,等下次生成再从请求池里调度不超过最大batch-size的请求进行处理。
※ 对请求按照Adapter聚在一起
为了尽量降低推理显存占用,就需要在每个batch的请求里尽量用最少的Adapters,即尽量把相同Adapter的请求放在一个batch里,这样每次需要从内存中取出的adapter的数量就会比较少,减少并行推理时的显存
※ 准入控制
S-LoRA还介绍了它在请求高并发状态的处理方式。对于每个请求,S-LoRA会预先衡量这个请求在当前状态下的处理时延用户是否能够接受,不能被接受的话,就会被直接抛弃掉。如果一下来的请求过多,它会选择只处理时间顺序相对靠后的满足时延的请求。相比于超时才显示请求失败这种硬性门槛,可以提高响应效率,对于完不成的请求就会直接显示失败,不需要用户等了指定时间超时了才显示。
※ 新的GPU算子
这一小节主要介绍的是S-LoRA采用的CUDA算子。论文中是放在了内存管理里介绍的,笔者认为这部分对于实现并行推理也很重要,就放在前面了。
为什么要用新的CUDA算子?原来我们在GPU中一般用到的矩阵计算算子是GEMM,GEMM是并行化处理矩阵的,我们在推理时,通过paddding把一个batch的所有序列填充到一样长度之后,每批次的输入,模型的各部分计算的矩阵大小是固定的,GEMM就可以实现各部分的并行计算。但是这样GPU的本身利用率就不高,再加上LoRA的Adapter的异构性(秩r的大小不一致),就导致原来的矩阵算子(GEMM)不能实现并行计算。于是,S-LoRA采用的是MBGMM和MBGMV算子,具体介绍读者可以参考下一段。
GEMM(通用矩阵乘法,动态计算图)->MBGMM(输入编码部分,sequence-level,triton)+MBGMV(解码部分,token-level,punica)
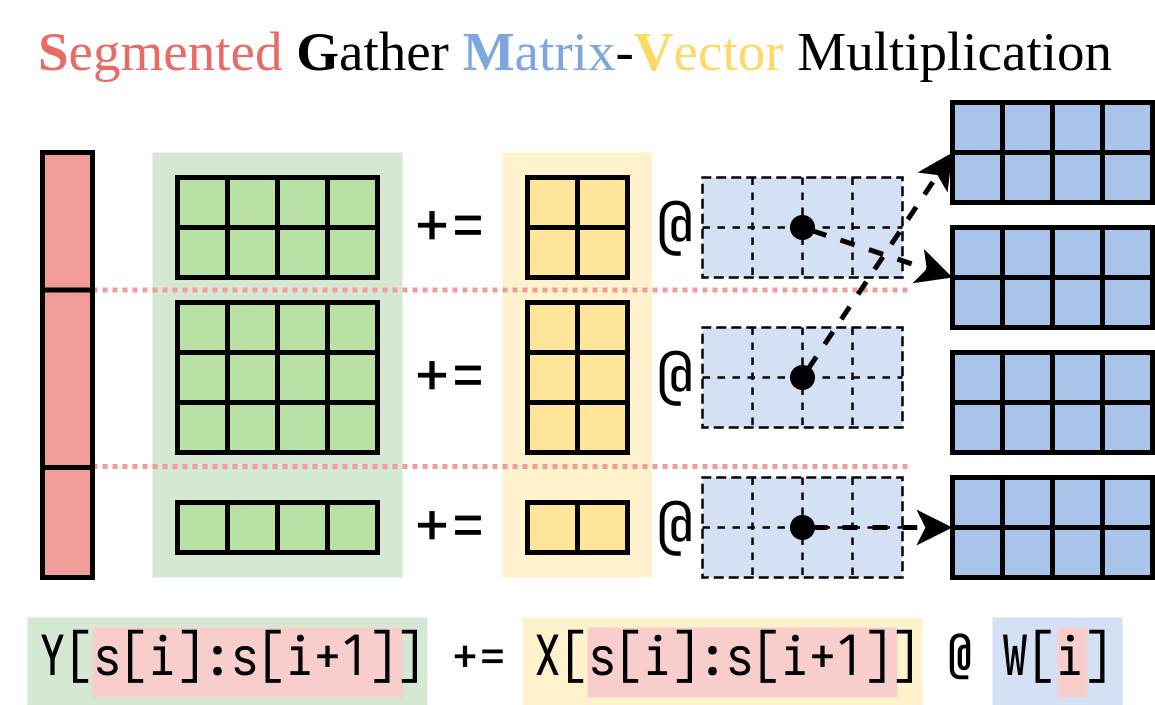
上图是Punica论文中的SGMV算子(即这里的MBGMV算子),相比于GEMM的固定矩阵相乘,这里是先把矩阵Gather到一起后,再相乘,即外层的Y+=X@W是一样的逻辑,但是内部的具体参数会随着请求对应的Adapter发生变化。
2 内存管理
S-LoRA的内存管理是延续了vLLM的Paged-Attention的页管理思想,用每个block table将逻辑地址和物理地址联系起来。S-LoRA就在Paged-Attention的基础上,在cache中除了Key和Value之外,还增加了对Adapter的参数的管理,如Figure 2 所示。
之所以可以这么设计,作者主要是认为LoRA的Adapters和Key&Value向量有着两点相似之处:
两者都是动态的,KV-cache是序列根据请求动态输入,请求结束就被销毁;adapter是每个请求如果用到了某个adapter就加载,下个batch没用到就移除;
两者的矩阵有一维是一样的,KV的矩阵形状是sequence-length×hidden-size,adapter的矩阵形状是rank-size×hidden-size,所以就算合在一起,也相对规整,可以减少显存碎片。
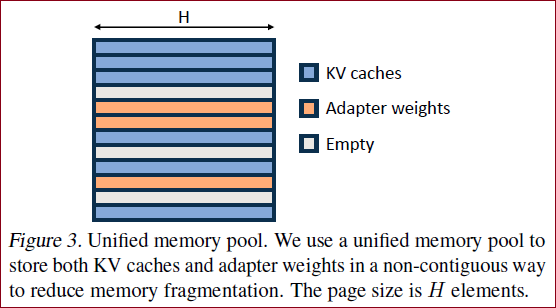
于是,增加Adapter weights之后的cache如Figure 3 所示。
此外,为了减少adapter weight从内存到显存的load时间,s-lora有个prefetch机制,就是会根据下一个batch的request中用到adapter,提前取出到cache里,减少loading的时间。
与为单个 base 模型提供服务相比,同时为多个 LoRA 适配卡提供服务会带来新的内存管理挑战。为了支持多个适配器,S-LoRA 将它们存储在主内存中,并将当前运行批所需的适配器权重动态加载到 GPU RAM 中。
在这个过程中,有两个明显的挑战。
首先是内存碎片,这是由于动态加载和卸载不同大小的适配器权重造成的。
其次是适配器加载和卸载带来的延迟开销。
为了有效解决这些难题,研究者提出了 「Unfied Paging」,并通过预取适配器权重将 I/O 与计算重叠。
Unified Paging
研究者将 PagedAttention 的想法扩展为统一分页(Unified Paging),后者除了管理 KV 缓存外,还管理适配器权重。统一分页使用统一内存池来联合管理 KV 缓存和适配器权重。
方法 为了实现这一点,他们首先为内存池静态分配一个大缓冲区,除了 base 模型权重和临时激活张量占用的空间外,该缓冲区使用所有可用空间。KV 缓存和适配器权重都以分页方式存储在内存池中,每页对应一个 H 向量。因此,序列长度为 S 的 KV 缓存张量占用 S 页,而 R 级的 LoRA 权重张量占用 R 页。Figure 3 展示了内存池布局,其中 KV 缓存和适配器权重以交错和非连续方式存储。这种方法大大减少了碎片,确保不同等级的适配器权重能以结构化和系统化的方式与动态 KV 缓存共存。
3 张量并行
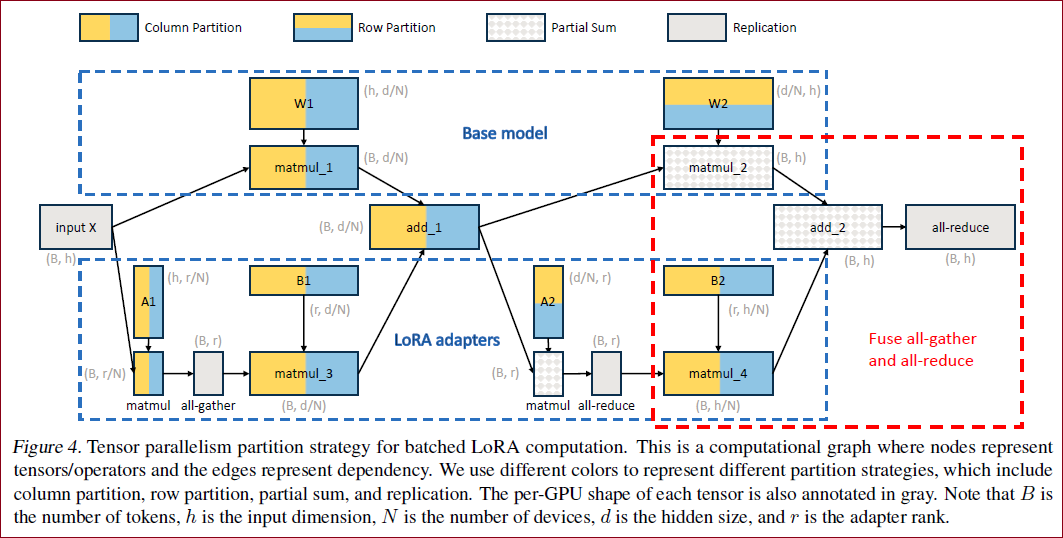
为了在显存不够的情况下,实现能够在多GPU上并行推理,又尽量减少通信损失,作者提出了张量并行的方案(类Megatron-LM)如Figure 4 所示。
此外,研究者为批量 LoRA 推断设计了新颖的张量并行策略,以支持大型 Transformer 模型的多 GPU 推断。
张量并行是应用最广泛的并行方法,因为它的单程序多数据模式简化了其实施和与现有系统的集成。
张量并行可以减少为大模型提供服务时每个 GPU 的内存使用量和延迟。
在本文设置中,额外的 LoRA 适配器引入了新的权重矩阵和矩阵乘法,这就需要为这些新增项目制定新的分区策略。
评估
最后,研究者通过为 Llama-7B/13B/30B/70B 提供服务来评估 S-LoRA。
结果
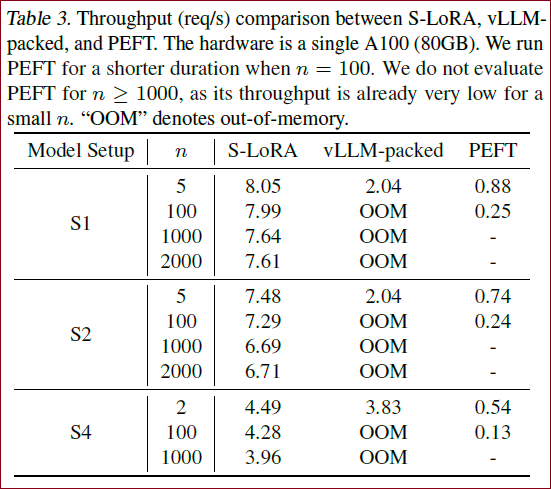
S-LoRA 可以在单个 GPU 或多个 GPU 上为数千个 LoRA 适配器提供服务,而且开销很小。
与最先进的参数高效微调库 Huggingface PEFT 相比,S-LoRA 的吞吐量最多可提高 30 倍。
与使用支持 LoRA 服务的高吞吐量服务系统 vLLM 相比,S-LoRA 可将吞吐量提高 4 倍,并将服务适配器的数量增加几个数量级。
补充
博文4 S-LoRA怎么用?
调用代码如下:github.com/vllm-projec… 通过代码可以看出,S-LoRA的调用很简单,处理base模型的常用参数温度等,只要在每个request的时候加上lora地址即可。目前仅支持LLaMa和mistral模型,在vLLM项目上是实验性集成,等待支持更多的大模型以及正式发布~
参考博文
点评:这篇博文主要把文章的创新点进行了概述。详略得当,但是看下来后个人发现似乎更偏向于系统上的创新,目前还比较难理解@2024年9月19日 12:21:13,后面再多看看吧。 ★★★★☆
【论文解读】S-LoRA: Serving thousands of concurrent LoRA Adapters
点评:这篇博文没有看完,只看了前面的梗概,等到使用这个技术的时候,再回头看看细节吧。
点评:★★★☆☆,对文章进行了通俗的要点概述,还不错。
点评:比博文1更加详细。 ★★★★☆
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。