AdaLoRA1 - 论文精读学习笔记
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
标签:Parameter-Efficient Fine-Tuning论文链接:AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
发表时间:2023
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
全文梗概
地位 在大模型微调的理论中,AdaLoRA方法是一个绕不开的部分。
这篇论文主要提出了一种新的自适应预算分配方法AdaLoRA,用于提高参数高效的微调性能。
AdaLoRA方法有效地解决了现有参数高效微调方法在预算分配上的不足,提高了在资源有限情况下的模型性能,为NLP领域的实际应用提供了新的思路和技术支持。
论文从研究背景,AdaLoRA方法,实验结果与对比分析等多个角度阐述了该方法的优势。
LoRA中,对每个矩阵使用相同的分支。不过这些分支的重要性是不一样的。当我们的budget有限的时候,我能就希望能够动态地设计LoRA分支的大小。对于不重要的地方,可以使用更小的维度。
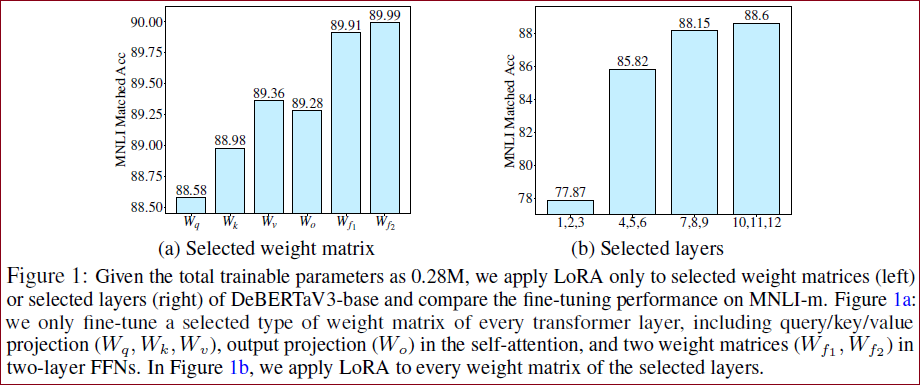
从Figure 1 (LoRA的局限性测试)不难看出,对于同一层不同的矩阵,或者对于不同的layer,微调他们带来的收益都是不一样的。
左图:针对不同模块进行LoRA微调,效果是不一样的。针对前馈网络FFN进行LoRA微调的效果要远优于自注意力模块的LoRA微调。右图:针对不同层进行LoRA微调,效果也是不一样的。10~12层的微调效果要远优于1~3层的微调效果。
博文4 摘要
问题:AdaLoRA也是解决全参数微调参数量过大、成本过高的问题。
解决方案:论文提出了AdaLoRA微调技术,是对LoRA的一种改进,LoRA没有考虑不同权重参数的重要性不同。AdaLoRA以奇异值分解的形式参数化增量更新,有效地修剪不重要更新的奇异值,避免了密集的精确SVD计算。
实验效果:在自然语言处理、问答和自然语言生成等多个预训练模型上的实验表明,AdaLoRA在低预算设置下,微调效果有显著的改进。
AdaLoRA的核心思想
通过上述实验可以看到:在理想状态下,微调关键模块/关键层的权重矩阵是最有效的,而微调不太重要的模块/层的权重矩阵不仅毫无意义,甚至有负面的影响。
AdaLoRA针对关键矩阵设置为高秩,对于不重要的矩阵修剪为低秩。设置为高秩的增量矩阵可以捕获更细粒度的特征。
AdaLoRA如何实现上述这种对秩的调整呢?答案是数学工具SVD(矩阵奇异值分解),SVD是将高维矩阵拆分为三个矩阵,即∆=PΛQ。
P和Q分别表示∆的左/右奇异向量,Λ表示∆的对角矩阵。
SVD在数据科学、机器学习中应用广泛,常用于降维、数据压缩、噪声过滤、文本数据的潜在语义结构提取等。
AdaLoRA通过对某层、某模块的重要性评分,动态调整
AdaLoRA构造了N个三元组,每个三元组Gi=(P, Λ, Q),AdaLoRA设计了一种重要性度量方法,重要性得分高的三元组被赋予高秩。
AdaLoRA的实验效果
针对DeBERTaV3-base进行自然语言理解(GLUE)、问题(SQuADv1)进行了评估,AdaLoRA有了更好的性能表现。
针对BART-large进行自然语言生成(XSum)进行了评估,AdaLoRA始终优于基线的性能。
背景
现状:预训练语言模型(PLMs)在NLP任务中表现出色,但全参数微调在大量下游任务中变得不可行。
挑战:现有方法如LoRA等通过低秩增量更新预训练权重,但均匀分配预算,忽略了不同权重参数的重要性。
动机:提出AdaLoRA以根据重要性分数自适应地分配参数预算。
在NLP领域,对于下游任务进行大型预训练语言模型的微调已经成为一种重要的做法。一般会采用对原有的预训练模型进行全量微调的方法来适配下游任务,但这种方法存在两个问题。
训练阶段。对于预训练模型进行微调的时候,为了更新权重参数,需要大量的显存来存储参数的梯度和优化器信息,在当今预训练模型的参数变得越来越大的情况下,针对下游任务微调门槛变得越来越高。
推理阶段。由于训练是对于模型参数进行全量的更新,所以对于多个下游任务需要为每个任务维护一个独立的大型模型,这样就导致在实际应用的时候浪费了不必要的存储空间。
为了解决这些问题,研究者提出了两个主要研究方向,以减少微调参数的数量,同时保持甚至提高预训练语言模型的性能。
方向一:添加小型网络模块:将小型网络模块添加到预训练模型中,保持基础模型保持不变的情况下仅针对每个任务微调这些模块,可以用于所有任务。这样只需引入和更新少量任务特定的参数,就可以适配下游的任务,大大提高了预训练模型的实用性。这类方法虽然大大减少了内存消耗,但是存在一些问题,比如引入了推理延时、比较难收敛。
方向二:下游任务增量更新:对预训练权重的增量更新进行建模,而无需修改模型架构,即
全文梗概
本文作者提出了AdaLoRA,它根据权重矩阵的重要性得分,在权重矩阵之间自适应地分配参数预算。
不能预先指定增量矩阵
需要找到更加重要的矩阵,分配更多的参数,裁剪不重要的矩阵。找到重要的矩阵,可以提升模型效果;而裁剪不重要的矩阵,可以降低参数计算量,降低模型效果差的风险。
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。具体做法如下:
调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确奇异值分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时保留未来恢复的可能性并稳定训练。
在训练损失中添加了额外的惩罚项,以规范奇异矩阵

方法
为了实现动态地调节Lora的rank的大小,首先将Lora改写为SVD的形式。当然,我们可以直接分解矩阵获得SVD,但是考虑到矩阵分解的代价比较大,所以直接学习这几个矩阵:
同时,对于
接下来的操作就是修建中间的特征值矩阵了。具体的做法是直接mask掉部分的特征值,保留PQ矩阵。
现在的核心问题就是,确定mask掉那些特征值,这里基本沿用了剪枝的做法。
最简单的做法,类似于 值减枝,直接将值大的特征值保留,对值小的特征值去除。但是这种做法过于简单。
所以本文使用一个 sensitivity:
考虑到batch具有一定的偶然性,所以在选取多个batch的结果进行平滑:
这里的U指的是 Uniform,代表重要性在不同batch之间的平滑程度。
方法概述:AdaLoRA通过奇异值分解(SVD)参数化增量更新,动态调整增量矩阵的秩以控制预算。
SVD参数化:增量更新
重要性评分:提出一种新颖的重要性度量,基于每个奇异值及其对应奇异向量的贡献来评分。
预算调度器:采用全局预算调度器,从略高于最终预算的初始值开始,逐渐减少到目标值。
实验与结果
数据集
在多个NLP任务(如GLUE、SQuAD、XSum等)上评估DeBERTaV3-base和BART-large等模型。
性能表现
AdaLoRA在低预算设置下表现尤为突出,如使用不到0.1%的全参数微调的可训练参数,在SQuAD2.0数据集上实现1.2%的F1提升。
对比分析
与LoRA等基线方法相比,AdaLoRA显示出显著的改进。(从整体的实验结果来看,AdaLoRA的微调效果全面优于LoRA,如Table 1 。)
通过实验证明,AdaLoRA 实现了在所有预算、所有数据集上与现有方法相比性能更好或相当的水平。 例如,当参数预算为
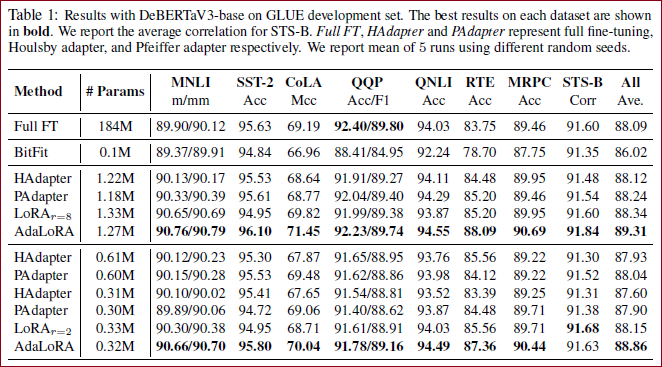
关键发现
增加计算预算,AdaLoRA的训练效果会显著优于LoRA。
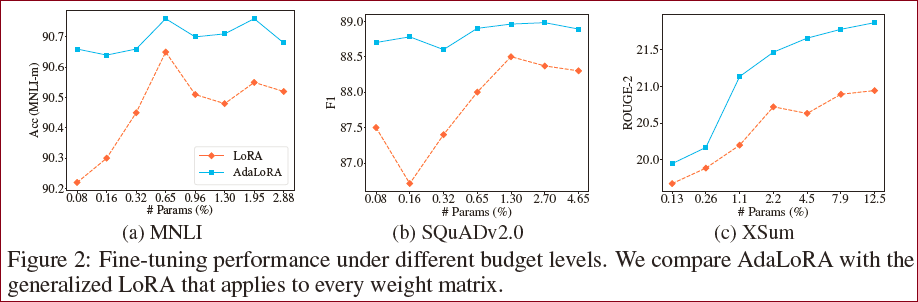
SVD降维、保证PQ矩阵的正交性,对AdaLoRA的训练效果都有影响。
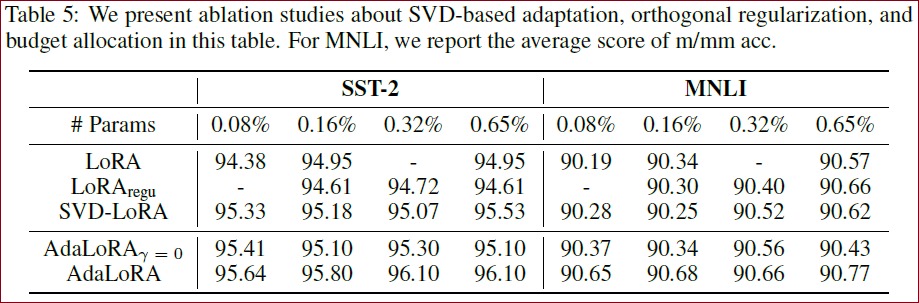
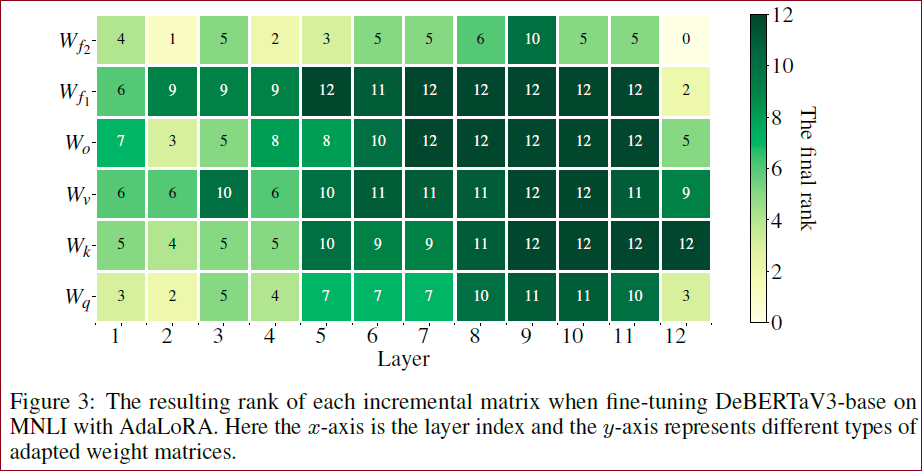
Transformer中,FNN的参数矩阵重要性要大于自注意力层的参数矩阵、顶层的参数矩阵重要性大于低层的参数矩阵重要性。
总结
优势与贡献
优势:相比传统的SVD方法,AdaLoRA避免了昂贵的SVD计算,同时保留了重要信息的恢复能力。
贡献:提出了一种新的自适应预算分配方法,提高了参数高效微调的性能,特别是在资源受限的场景下。
未来工作
探索方向
未来可以进一步优化重要性评分和预算调度策略,以及将AdaLoRA应用于更多类型的预训练模型和任务。
该论文对AI大模型微调的从业者带来一些启发,也可以作为微调的入门论文。
博文4 从上述论文解读中,我们收获了如下技术观点:
AdaLoRA的核心思想:采用SVD、正则损失、二次平滑的重要性评估,精准地控制每一层的参数矩阵降维。
AdaLoRA的关键发现:
SVD降维、保证PQ矩阵的正交性,对AdaLoRA的训练效果都有影响。
Transformer中,FNN的参数矩阵重要性要大于自注意力层的参数矩阵、顶层的参数矩阵重要性大于低层的参数矩阵重要性。
阅读AdaLoRA最大的感触就是数学的奇妙,AdaLoRA是一个主要依赖数学公式推导解决算法问题的典型代表。
参考博文
论文《AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning》浅析
点评:该博文对论文进行了文字梳理,但是非常有逻辑。内容虽短,但很赞! ★★★★☆
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
点评:这篇博文是以文字的形式对文章进行了概况,还是比较到位的。★★★☆☆。
ADAPTIVE BUDGET ALLOCATION FOR PARAMETER- EFFICIENT FINE-TUNING
点评:怎么说呢,这篇文章很奇怪,但是似乎又把重点都突出了。及格分吧:★★★☆☆。
【chatGPT】学习笔记51-LLM微调技术之AdaLoRA
点评:这篇博文对文章的细节说的很详细,如果每篇文章都按照这样的方式来吸收,应该很快会有idea!★★★★☆!
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。