Punica1 - 论文精读学习笔记
Punica: Multi-tenant lora serving
标签:Parameter-Efficient Fine-Tuning论文链接:Punica: Multi-tenant lora serving
发表时间:2024
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
背景
低秩适应(LoRA)是一种高效添加新知识到预训练LLM的方法。尽管预训练的LLM需要数百GB的存储空间,但LoRA微调的模型只增加了1%的存储和内存开销。
LoRA(低秩适应)核心思想:保留预训练模型的权重,同时在每一层的Transformer结构中引入可训练的秩分解矩阵,从而显著减少了需要训练的参数的数量,降低了训练的成本和时间,同时在加载特定模型时只需要加载对应的秩分解矩阵,大大缩减了模型加载时间。
※ Punica允许以运行一个模型的成本运行多个LoRA微调模型。
如何实现?
全文概述
Punica系统:设计了一个CUDA内核,叫做分段聚合矩阵向量乘法(SGMV),它可以实现对不同的LoRA模型的并行计算,并且只需要在GPU内存中存储一份预训练模型的权重,从而提高了GPU的效率和利用率。Punica还设计了新的调度机制来合并多租户的LoRA工作负载,从而释放GPU资源
SGMV:可以实现对不同的LoRA模型的请求进行批量处理,从而实现多个LoRA模型的并行执行。
按需加载的机制:在毫秒级的延迟内,将LoRA模型的权重从主存储器复制到GPU内存中,从而避免了模型切换的开销。
调度机制:对于新请求,Punica将它分配到一小部分活跃的GPU上,确保充分利用GPU。只有当现有GPU都被充分利用时,Punica才会分配额外的GPU。对于已经存在的请求,Punica定期将它们迁移到其他的GPU上,从而实现工作负载的合并。
方法
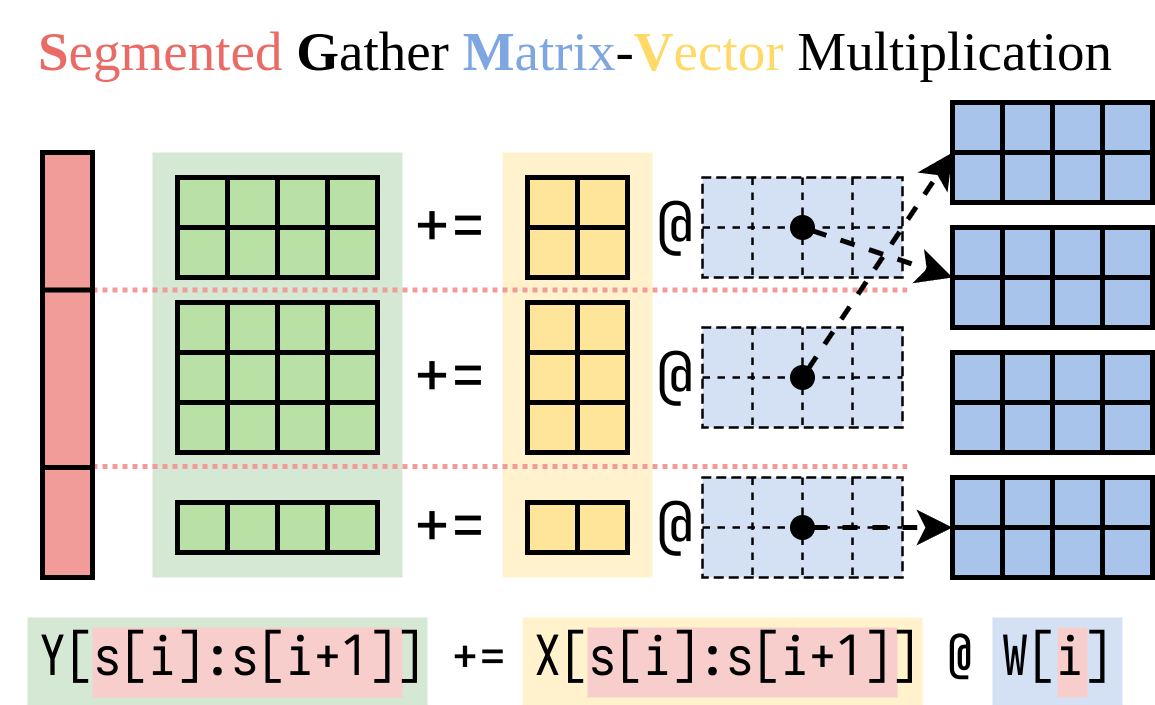
假设W的形状为[H1, H2],它是预训练模型的权重,LoRA会添加两个小矩阵A形状为[H1, r]和B形状为[r, H2]。在微调模型上运行输入x的过程为y := x @ (W + A@B),这与y := x@W + x@A@B相同。
当有n个LoRA模型时,会有A1, B1, A2, B2, ..., An, Bn。
给定输入批次
X := (x1,x2,...,xn),映射到每个LoRA模型,输出为Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn)。左侧部分在预训练模型上计算输入批次,非常高效。由于强大的批处理效应,延迟几乎与只有一个输入时相同。
我们找到了一种高效计算右侧部分(LoRA附加部分)的方法。我们将此操作封装在一个CUDA内核中,称为分段聚合矩阵向量乘法(SGMV),如下图所示。
在下面的微基准测试图中,我们可以观察到预训练模型的强大批处理效应。
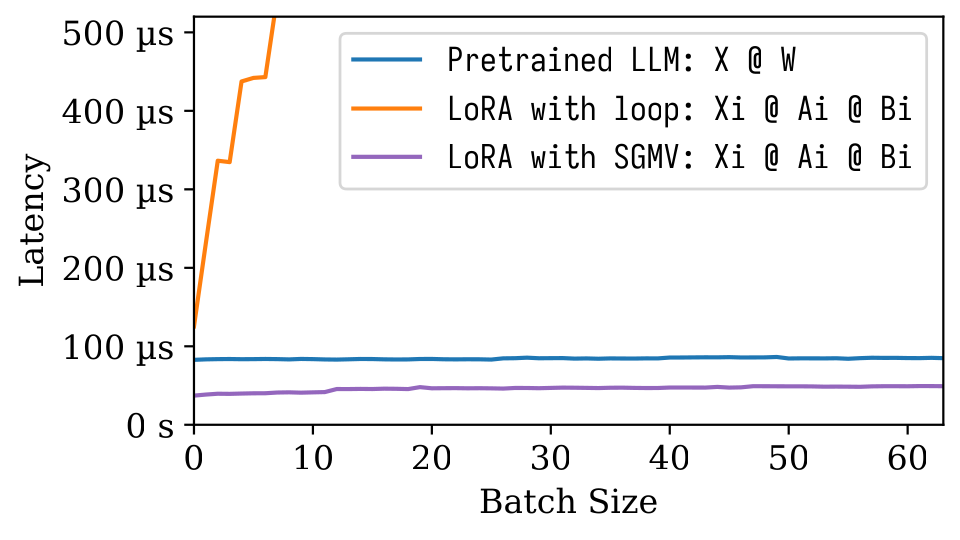
橙色线表示LoRA的朴素实现速度较慢。通过SGMV实现的LoRA非常高效,并且保留了强大的批处理效应。
下图显示了Punica与其他系统的文本生成吞吐量比较,包括HuggingFace Transformers、DeepSpeed、FasterTransformer、vLLM。
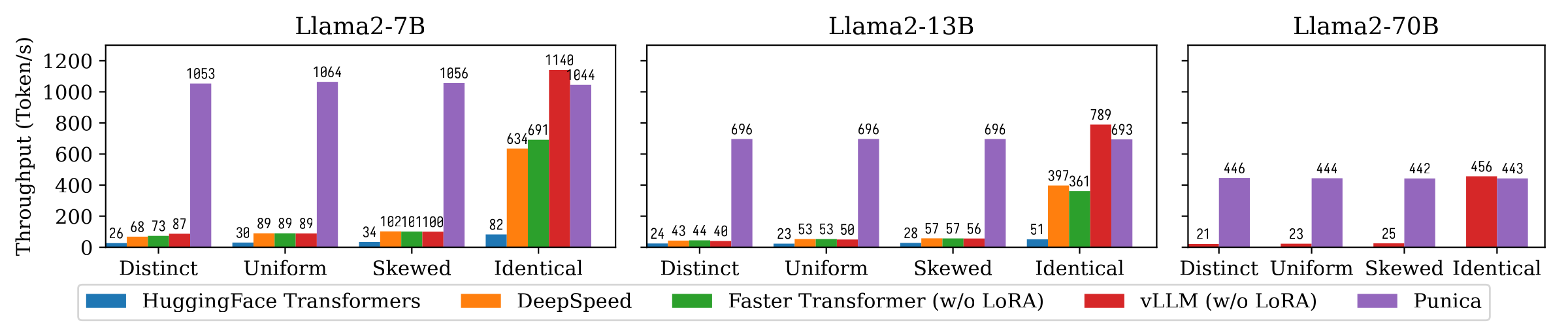
基准测试考虑了不同LoRA模型受欢迎度的设置。
Distinct表示每个请求对应不同的LoRA模型。
Identical表示所有请求都对应相同的LoRA模型。
Uniform和Skewed介于两者之间。
Punica的吞吐量是当前最先进系统的12倍。
安装
您可以通过二进制包安装Punica,也可以从源代码构建安装。
从二进制包安装
优点:无需编译。安装速度快。
缺点:可能与您的CUDA版本、CUDA架构、PyTorch版本或Python版本不匹配。
当前预编译版本:
CUDA: 11.8, 12.1
Python: 3.10, 3.11
TORCH_CUDA_ARCH_LIST:
8.0 8.6 8.9+PTX
xxxxxxxxxx31pip install ninja torch2pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple3# 注意:将cu121更改为您的CUDA版本。从源代码构建
xxxxxxxxxx141# 请在安装Punica前先安装torch2pip install ninja numpy torch3
4# 克隆Punica5git clone https://github.com/punica-ai/punica.git6cd punica7git submodule sync8git submodule update --init9
10# 如果在编译时遇到问题,请将TORCH_CUDA_ARCH_LIST设置为您的CUDA架构。11# export TORCH_CUDA_ARCH_LIST="8.0"12
13# 构建并安装Punica14pip install -v --no-build-isolation .
示例
服务多个LoRA模型
见上面的演示。
微调并转换为Punica格式并使用Punica服务
见examples/finetune/
文本生成基准测试
xxxxxxxxxx11python -m benchmarks.bench_textgen_lora --system punica --batch-size 32
参考博文
点评:从内容判断,应该是作者团撰写的文稿,有演示,有说明,很不错的博文。值得反复观看。★★★★☆
PUNICA: MULTI-TENANT LORA SERVING
点评:★★★☆☆,对文章内容进行文字概述。
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。