MLLM Survey1 - 论文精读学习笔记
Efficient Multimodal Large Language Models: A Survey
标签:Multimodal Large Language Models论文链接:Efficient Multimodal Large Language Models: A Survey
发表时间:2024
You are what you eat.
And I'm cooking what I eat! :)
目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
预备知识
[1] Baltrušaitis T, Ahuja C, Morency L-P. Multimodal machine learning: A survey and taxonomy[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(2): 423-443.
Modality:模态,某事发生或经历的方式;
Multimodal:多模态
natural language :which can be both written or spoken 自然语言
visual signals: which are often represented with images or videos 视觉图片以及视频
vocal signals: which encode sounds and para-verbal information such as prosody and vocal expressions 声音
多模态面临的挑战
1 表征(Representation):如何以利用多种模态的互补性和冗余性的方式表示和总结多模态数据;
● 多模态数据的异质性:语言通常是象征性的,而音频和视觉形式将被表示为信号
2 翻译(Translation):如何将数据从一种模态转换(映射)到另一种模态
● 模态之间的关系通常是开放式的或主观的:存在多种描述图像的正确方法,并且可能不存在一种完美的翻译
3 对齐(Alignment):从两个或多个不同的模态中识别(子)元素之间的直接关系
4 融合(Fusion):结合来自两种或多种模态的信息来执行预测
5 联合学习(Co-learning):在模态、它们的表示和它们的预测模型之间转移知识
协同训练co-training 零样本学习zero shot learning
任务
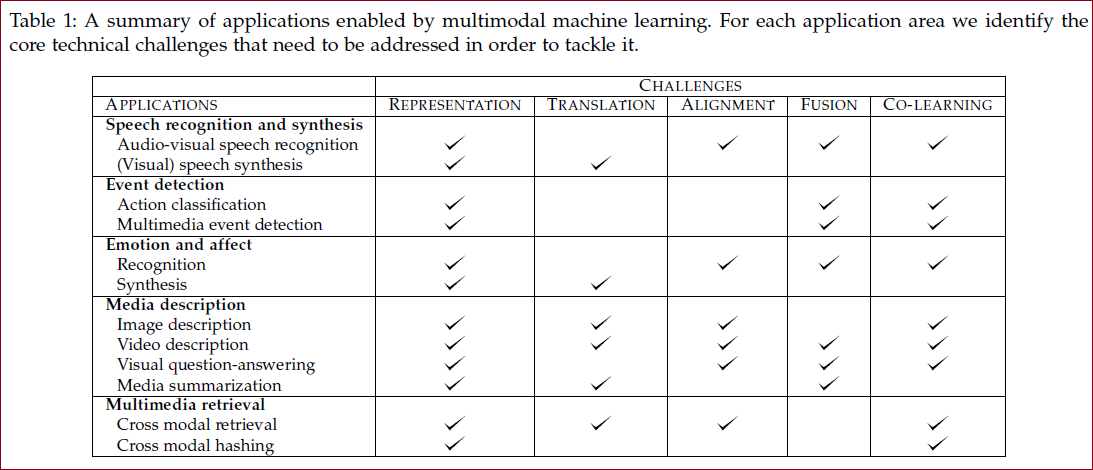
表征 Representation
解释:试图通过各模态的信息找到某种对多模态信息的统一表示
难题:如何组合来自异构来源的数据;如何处理不同级别的噪音;以及如何处理丢失的数据。
好的表征的特点:
平滑度 smoothness
时间和空间连贯性 temporal and spatial coherence
稀疏性 sparsity
自然聚类 natural clustering
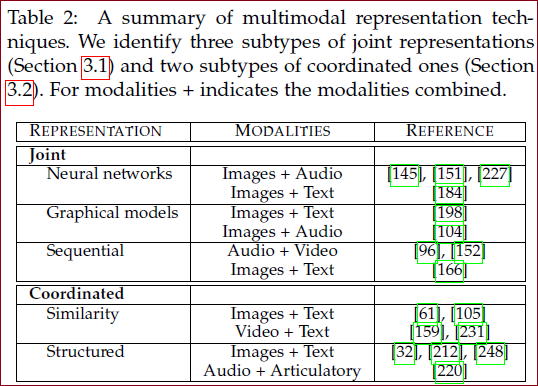
两种表征思路:
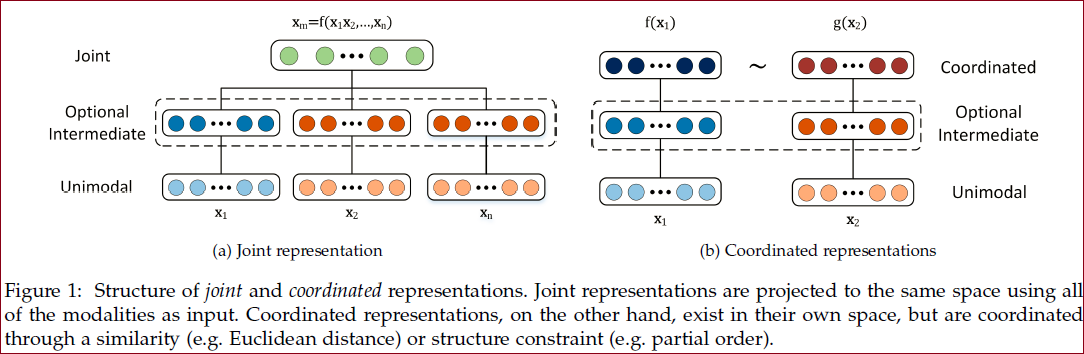
联合 joint
单模态的表示联合投影到多模态的联合表示;
神经网络模型:通常使用最后或倒数第二个神经层作为单模态数据表示的一种形式,为了使用神经网络构建多模态表示,每个模态都从几个单独的神经层开始,然后是一个隐藏层,将模态投影到联合空间,然后联合多模态表示本身通过多个隐藏层或直接用于预测。
概率图模型 Probabilistic graphical
RNN序列模型
tips:autoencoder models 自动编码器
协调 coordinated
每个模态学习单独的表示,并通过约束进行协调;
基于相似度的模型:最小化协调空间中模态之间的距离。
结构化协调模型:用于跨模态散列——将高维数据压缩成具有相似对象的相似二进制代码的紧凑二进制代码。
代表:
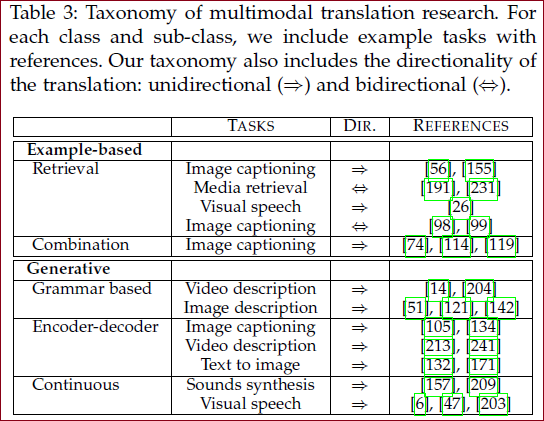
翻译 Translation
解释:将一种模态数据映射为另一种模态数据
两种思路:
example-based 基于示例的
翻译 跨模式检索 图像描述......
generative 生成
基于语法(grammar-based), 编码器-解码器模型(encoder-decoder), 连续生成(continuous generation)【基于源模态输入流连续生成目标模态,最适合在时间序列之间进行转换】
代表:
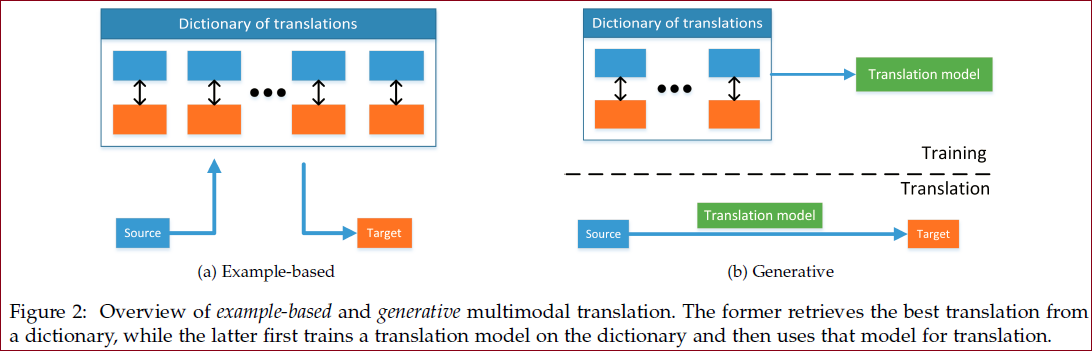
对齐 Alignment
解释:从两个甚至多个模态中寻找事物子成份之间的关系和联系。比如给定一张图片和图片的描述,找到图中的某个区域以及这个区域在描述中对应的表述。又比如给定一个美食制作视频和对应的菜谱,实现菜谱中的步骤描述与视频分段的对应。
两种思路:
显式对齐 explicit
重点是相似性度量。两种方法:无监督(动态时间扭曲 DTW) 、弱监督
隐式对齐 implicit
学习如何在模型训练期间潜在地对齐数据。两种方法:图模型、神经网络模型(使用attention机制)
图像字幕中,注意力机制将允许解码器(通常是 RNN)在生成每个连续单词时专注于图像的特定部分;
问答任务,允许将问题中的单词与信息源的子组件(例如一段文本[236]、图像[65]或视频序列)对齐。
融合 Fusion
解释:从多个模态信息中整合信息来完成分类或回归任务
融合的价值:
在观察同一个现象时引入多个模态,可能带来更健壮(robust)的预测;
接触多个模态的信息,可能让我们捕捉到互补的信息(complementary information),尤其是这些信息在单模态下并不"可见"时;
一个多模态系统在缺失某一个模态时依旧能工作;
两种思路:
无模型 model-agnostic
早期(基于特征,在特征被提取后立即集成(通常通过简单地连接它们的表示),比较简单)
晚期(基于决策,在每种模态做出决定(例如分类或回归)后执行整合,方法包括:平均、投票方案、基于信道噪声的加权、信号方差、学习模型,允许为每个模态使用不同的模型,因为不同的预测器可以更好地对每个单独的模态进行建模,从而提供更大的灵活性;当缺少一种或多种模态时,它可以更轻松地进行预测,甚至可以在没有并行数据时进行训练,然而忽略了模态之间的低级交互)
混合融合(早期融合和单个单峰预测器的输出)
基于模型 model-based
Multiple Kernel learning(MKL),多核学习(将不同的核用于不同的数据模态/视图)
Graphical models,图模型 后续可以看看
Neural Networks,神经网络 循环神经网路,进行端到端的训练
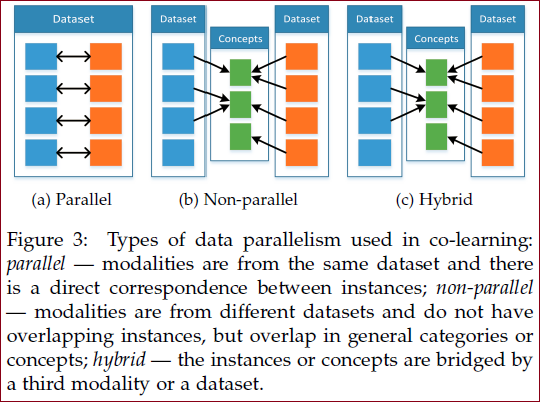
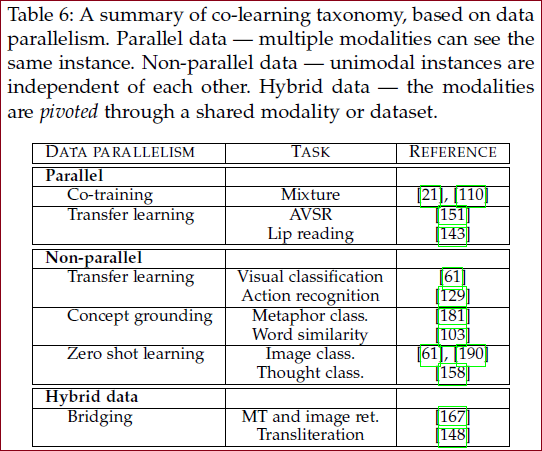
共同学习 Co-learning
解释:通过利用来自另一种(资源丰富)模态的知识来帮助(资源贫乏)模态建模;
辅助模态(helper modality)通常只参与模型的训练过程,并不参与模型的测试使用过程。
三种方法:
并行
需要训练数据集,其中来自一种模态的观察结果与来自其他模态的观察结果直接相关;协同训练、表示学习、迁移学习
非并行
不需要来自不同模式的观察之间的直接联系,通常通过使用类别重叠来实现共同学习;零样本学习ZSL。
混合
通过共享模式或数据集桥接
背景
博文1 在当前人工智能发展的浪潮中,多模态大型语言模型(Multimodal Large Language Models, MLLMs)凭借其强大的视觉问答与理解推理能力,正在成为引领科技前沿的关键技术之一。然而,高昂的训练和推理成本,以及庞大的模型体积限制了这些模型在学术界和工业界的广泛应用,特别是在边缘计算场景下。今天,我们要为大家介绍的是一个旨在解决这一问题的重要项目——“高效多模态大语言模型综述”(《Efficient Multimodal Large Language Models: A Survey》),由腾讯优图实验室、上海交通大学等多家研究机构共同完成。
矛盾点 边缘计算场景下,各端计算能力弱 vs. 大模型体积庞大、训练与推理成本高
全文概述
技术剖析:打造轻量级多模态大模型新路径
本项目不仅全面回顾了现有高效MLLMs的发展历程,还深入探讨了各种高效的结构和策略,为未来的科研人员提供了宝贵的参考指南。通过对比不同模型的设计理念、参数规模、架构特点和技术路线图,读者可以清晰地了解到每个模型的优势和局限性。
例如,在MobileVLM中,采用CLIP ViT-L/14作为视觉编码器,并结合MobileLLaMA小尺寸语言模型,成功实现了模型的高效率与轻量化;而Imp-v1则聚焦于小规模语言模型的实用性和效能评估。通过对这17种主流高效MMLMs的总结,我们能够看出研究者们如何从不同的角度探索提升模型性能的同时降低资源消耗的方法。
应用场景:从理论到实践的无缝衔接
高效MLLMs的应用范围广泛,无论是智能客服系统中的快速响应,还是移动设备上的低功耗运行,甚至是嵌入式物联网设备的实时交互,都能找到它们的身影。随着技术的不断进步,这些轻量级模型将更加适应各种复杂环境下的需求,成为AI普及化道路上不可或缺的一环。
比如,在边缘计算领域,由于网络连接不稳定或带宽受限,传统的大模型往往无法达到理想的效果。这时,高效MLLMs的低延迟特性和较小的存储需求就显得尤为重要。此外,在智能家居、可穿戴设备等场合,资源约束更是驱动着模型向更小型化方向发展。
特色亮点:开拓创新,共绘未来蓝图
《Efficient Multimodal Large Language Models: A Survey》不仅仅是一份详尽的技术报告,它更是对未来趋势的一种前瞻性预测。项目团队精心梳理了从2023年至今的多项研究成果,每项成果都代表了研究领域的最新进展。不仅如此,该项目还特别强调了持续更新的原则,承诺将积极跟踪并整合最新的科研信息,确保资料的时效性和完整性。
该调查报告不仅涵盖了众多前沿技术细节,如视觉编码器的优化设计、语言模型的小型化策略、跨模态融合方法的革新等,而且还对每一种策略的有效性和适用场景进行了细致分析。对于那些渴望深入了解多模态大模型最新动态的研究者而言,《Efficient Multimodal Large Language Models: A Survey》无疑是不可多得的学习宝库。
总之,“高效多模态大语言模型综述”以其详实的内容、专业的视角和前瞻性的思考,成为了推进高效MLLMs研究与发展的重要驱动力。无论你是从事相关技术研发的专业人士,还是对AI领域感兴趣的爱好者,都不应错过这一宝藏资源。
参考博文
论文阅读:《Multimodal Machine Learning:A Survey and Taxonomy》
点评:★★★★☆,对于拓展多模态非常重要,这篇文章很赞!!
引领高效多模态大语言模型的未来 —— 推荐《Efficient Multimodal Large Language Models: A Survey》
点评:★★★★☆,这是对文章的概述,就3段话,已经摘录进博文中,但是从这3段话可以看出,这篇文章值得一读!!
【MLLM研究综述】《Efficient Multimodal Large Language Models: A Survey》——腾讯最新多模态大模型综述
点评:★★☆☆☆,内容太多了!!
2024年9月25日 16:05:48看了一遍,真的写的不错!值得再读!!!
A Survey on Multimodal Large Language Models
点评:★★★☆☆,不是这篇blog题目对应的论文,但是依然值得一看!!
A Survey on Multimodal Large Language Models
点评:★★★☆☆,(同博文4)不是这篇blog题目对应的论文,但是依然值得一看!!
今日arXiv最热NLP大模型论文:一文读懂多模态大模型的进化之路
The (R)Evolution of Multimodal Large Language Models :A Survey(点击直接下载pdf文件)
点评:★★★☆☆,不是这篇blog题目对应的论文,但是依然值得一看!!
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。